|
Virtual Visual Hulls:
Example-Based 3D Shape Inference from Silhouettes |
|
Kristen Grauman, Gregory Shakhnarovich,
and Trevor Darrell |
|
|
|
Abstract We present a method for estimating the 3D
visual hull of an object from a known class given a single silhouette or
sequence of silhouettes observed from an unknown viewpoint. A
non-parametric density model of object shape is learned for the given object
class by collecting multi-view silhouette examples from calibrated, though
possibly varied, camera rigs. To infer a 3D shape from a single input
silhouette, we search for 3D shapes which maximize the posterior given the
observed contour. The input is matched to component single views of the
multi-view training examples. A set of viewpoint-aligned virtual views are
generated from the visual hulls corresponding to these examples. The
most likely visual hull for the input is then found by interpolating between
the contours of these aligned views. When the underlying shape is ambiguous
given a single view silhouette, we produce multiple visual hull hypotheses;
if a sequence of input images is available, a dynamic programming approach is
applied to find the maximum likelihood path through the feasible hypotheses
over time. We show results of our algorithm on real and synthetic images of
people. Estimating the 3D shape of an object is an
important vision and graphics problem, with numerous applications in areas
such as virtual reality, image-based rendering, or view-invariant
recognition. However, current techniques are still expensive or
restrictive. Active sensing techniques can build accurate models
quickly, but require scanning a physical object. Structure from motion
(SFM) or from multiple views is non-invasive, but requires a set of
comprehensive views of an object. Most such algorithms rely on
establishing point or line correspondences between images and frames, yet
smooth surfaces without a prominent texture and wide-baseline cameras make
correspondences difficult and unreliable to determine. Moreover, in the case
of Shape-From-Silhouettes, the occluding contours of the object are the only
feature available to register the images. Current techniques for 3D
reconstruction from silhouettes with an uncalibrated
camera are constrained to the cases where the camera motion is of a known
type (e.g., circular, curvilinear, or close to linear.) In this work we show that for shapes
representing a particular object class, visual hulls can be inferred from a
single silhouette or sequence of silhouettes. Object class knowledge
provides additional information about the object's structure and the
covariate behavior of its multiple views. We develop a probabilistic
method for estimating the visual hull (VH) of an object of a known class
given only a single silhouette observed from an unknown viewpoint, with the
object at an unknown orientation (and unknown articulated pose, in the case
of non-rigid objects). We also develop a dynamic programming method for
the case when sequential data is available, so that some of the ambiguities
inherent in silhouettes may be eliminated by incorporating information
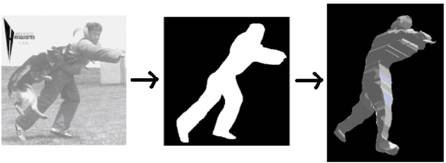
revealed by how the object (or camera) moves. Below are some example results.
Example result on real sequential data. Top row shows
input sequence, middle
An example of four virtual visual
hull hypotheses found by our system for a single input silhouette (top). Each
row corresponds to a different hypothesis; three different viewpoints are
rendered for each hypothesis. Stick figures beside each row give that VH’s underlying 3D pose, retrieved by interpolating
the poses of the examples which built the VHs.
|

