© Springer-Verlag
"Interactions of Abstractions in Programming," Abstraction, Reformulation, and Approximation: 4th International Symposium (SARA-2000), Horseshoe Bay, TX, July 2000. Lecture Notes in Artificial Intelligence, vol. 1864, pp. 185-201, ISBN 3-540-67839-5, Springer-Verlag, 2000.
Gordon S. Novak Jr.
University of Texas at Austin
Austin, TX 78712, USA
novak@cs.utexas.edu
http://www.cs.utexas.edu/users/novak
Computer programs written by humans are largely composed of instances of well-understood data and procedural abstractions. Clearly, it should be possible to generate programs automatically by reuse of abstract components. However, despite much effort, the use of abstract components in building practical software remains limited.We argue that software components constrain and parameterize each other in complex ways. Commonly used means of parameterization of components are too simple to represent the multiple views of components used by human programmers. In order for automatic generation of application software from components to be successful, constraints between abstract components must be represented, propagated, and where possible satisfied by inference.
A simple application program is analyzed in detail, and its abstract components and their interactions are identified. This analysis shows that even in a small program the abstractions are tightly interwoven in the code. We show how this code can be derived by composition of separate generic program components using view types. Next we consider how the view types can be constructed from a minimal specification provided by the user.
The goal of constructing software applications from mass-produced software components has been sought since McIlroy's classic paper [mcilroy68] in 1968. Although there is some reuse of components in applications programming today, much code is still written by hand in languages that are little changed from the Fortran of the 1950's.
Despite the many approaches to component technology, why have reusable software components had so little impact [perry99] ? We argue that existing component technologies are not abstract enough and that automated tools for combining and specializing abstract components are needed.
When considering a programming technology, the reader may naturally be tempted to think ``this problem could be solved using language X.'' Of course this is true: any problem can be solved in any of the programming languages. However, the software problem can be solved only by a method of programming that meets all of the following criteria:
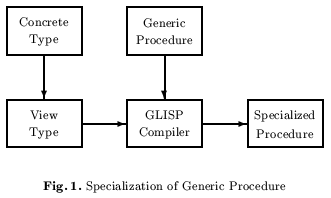
We have previously developed systems that can specialize generic procedures (we use the terms generic procedure and abstract procedure synonymously) for an application based on views. A view [novak:tose95][novak:tose97] makes a concrete (application) data type appear to be an instance of an abstract type by defining the properties expected by methods of the abstract type in terms of the concrete type. Figure figspec shows how a generic procedure is specialized through a view type. For example, an abstract type circle may expect a radius, but an application type pizza may be defined in terms of diameter; a view type pizza-as-circle defines the radius needed by circle in terms of diameter of the pizza, allowing generic procedures of circle to be specialized for type pizza. A view is analogous to a wrapper type in OOP [gamma95], except that a view is virtual and does not modify or add to the concrete type. Recursive in-line compilation and partial evaluation of the translation from concrete type to abstract type result in efficient code.
We have produced an Automatic Programming Server (APS), available over the web. (See http://www.cs.utexas.edu/users/novak . A Unix system running X windows is needed to run the server; any browser can view examples and documentation.) APS allows the user to describe application data and make views of that data as abstract types known to the system (including both mathematical types, e.g. circle, and data structure types, e.g. an AVL tree). Once a view has been made, APS can synthesize specialized versions of generic procedures and deliver them to the user in the desired language (currently Lisp, C, C++, Java, or Pascal). APS allows hundreds of lines of correct application code to be obtained in a few minutes of interaction. A related system, VIP [novak:caia94] (also available on the web), allows scientific programs to be constructed graphically from diagrams of physical and mathematical principles and relations between them.
APS and VIP synthesize useful program components, with the human user performing the overall system design and design of data structures. The success of APS and VIP suggests that it should be possible to generate whole application programs by describing the programs at a high level of abstraction and then synthesizing the code automatically by specialization of generic procedures, as APS does presently. This paper considers the kinds of abstractions and interactions of abstractions that are necessary to enable such synthesis.
The paper is organized as follows. The interactions of abstractions in programs are illustrated by a detailed analysis of a simple hand-written program. Next, we show how view types in the GLISP language [novak:glisp] allow a similar program to be compiled automatically from a set of reusable generic components. The view types needed are complex; automated support is needed to allow these types to be constructed from a minimal specification using constraint propagation and inference. A final section considers related work.
To illustrate the interactions of abstractions in programs, we consider a small hand-written Lisp program: given as input a list of sublists, each of which has the format (key n), the program sums the values n for each key; an association list alist is used to accumulate the answer. For example, given the input list ((a 3) (b 2) (c 1) (a 5) (c 7)) the program produces the output ((C 8) (B 2) (A 8)).
(defun alsum (lst)
(let ((alist nil) entry)
(dolist (item (identity lst))
(setq entry
(or (assoc (car item) alist)
(progn (push (list (car item) 0 )
alist)
(assoc (car item) alist))))
( incf (cadr entry) (cadr item) ) )
alist))
Although this is a very small application program, it is built from numerous abstract software components. Different type fonts are used to indicate code associated with the abstract software components described below; a glance at the code shows that the different components are tightly interwoven in the code.
The overall program is an instance of an abstract program we call Iterate-Accumulate: the program iterates through some sequence derived from its input, producing a sequence of items, then accumulates some aspect of the items. This abstract program encompasses a wide range of possible applications, such as updating a bank account, averaging grades, counting occurrences of different words in a text file, numerically integrating a function, computing the area of a polygon, etc. In the above example, the accumulator is also an abstract procedure called Find-Update, which looks up a key in some indexing structure, then updates the entry that is found. The abstract programs Iterate-Accumulate and Find-Update are parameterized in the following ways:
How do we know that these are the correct abstractions for this program? A substitution test is useful: the application could be modified by substitution of a different component for each of the above components, affecting only the corresponding parts of the program code. For example, an array could be substituted for the linked list input, requiring the iterator to be changed; the alist of item 4 could be changed by using an AVL tree to index keys (giving faster lookup at the cost of more code); the adder accumulator of item 5 could be changed to accumulate the product of numbers rather than their sum.
We claim that, with few exceptions, effectively reusable software components must be abstract. (The exceptions are components such as math functions and matrix subroutines, where the arguments will always be of a simple type. Such components are the ones most commonly reused at present.) Without abstraction, there must be a combinatoric number of versions of a component (e.g. Batory [batory93] found that there are over 500 versions of components in the Booch library, corresponding to combinations of many fewer features of the components); this quickly becomes untenable. We take the opposite position: there should be only one abstract version of a component that should serve for all uses.
If there is only a single abstract version of a component, it clearly will have to be specialized for each application. The GLISP compiler can specialize a generic procedure through views. Specialization capabilities include data structure variations, changes in the set of parameters used to describe a mathematical concept, changes in units of measurement, and algorithm options (partial evaluation of conditional tests causes desired code to be retained and undesired code to vanish). Specialized procedures are mechanically translated into the desired target language; this makes the languages used for the tools and generic procedures (Lisp and GLISP) independent of the language used for an application and allows a single set of tools and generics to satisfy all uses.
Existing systems such as APS allow individual software components to be specialized for an application. Our goal is:
The abstract procedural components Iterate-Accumulate and Find-Update are shown below. Although the GLISP language allows message sends to be written in functional form (as in CLOS), we have shown them using the send syntax for emphasis. The syntax (send acc initialize), meaning send to the object acc a message whose selector is initialize, would be written (initialize acc) using the functional syntax.
(gldefun itacc (input:anything acc:anything)
(let (seq item iter)
(acc := (a (typeof acc)))
(send acc initialize)
(seq := (send input sequence))
(iter := (send seq make-iterator))
(while (not (send iter done))
(item := (send iter next))
(acc := (send acc update item)) )
acc))
(gldefun findupd (coll:anything item:anything)
(let (entry)
(entry := (send coll find (send item key)))
(if (null entry)
(coll := (send coll insert (send item key)))
(entry := (send coll find (send item key))))
(send entry update item)
coll ))
In the generic procedure itacc, the arguments are both described as having type anything; when the procedure is specialized, actual types are substituted. Generic procedures are written in such a way that all type parameters are the types of arguments (or can be derived from argument types). Any types that were hard-coded within a generic would be unchangeable, and thus would limit its reusability. The parameter acc is purely a type parameter, since this variable is initialized within the procedure. (It is desirable to eliminate acc as a formal argument and convert it a local variable, but we have not implemented this.) The code (a (typeof acc)) causes creation of a new data object whose type is the same as the type of the ``argument'' acc.
The code (seq := (send input sequence)) extracts the desired sequence from the input. Note that this code assumes that the actual input type is wrapped by a view type that will implement the sequence method; this view is specified as the type when itacc is specialized. This view type is application dependent: the input could have multiple sequences, and there could be variations of those sequences, e.g. employees with dependents, that are defined. The sequence is assumed to define a way to make an iterator for itself, producing items; the item must have a wrapped type, since the features to be extracted from the item (in this case, the key value used for indexing and the value to be accumulated) are application-dependent. The sequence must also be wrapped to produce items with the proper view type wrapper.
GLISP type definitions for the abstract components list-iterator, alist, and adder are shown below. Each definition gives the name of the type, a data structure description, and definitions of methods associated with the type. For example, the generic alist has a data structure that is a listof elements, each of which is a cons of a key field and arbitrary rest data; the messages initialize, find, and insert are defined for the alist as small bits of code that are expanded inline when used.
(list-iterator (lst (listof anything))
msg ((done ((null lst)))
(next ((pop lst)))))
(alist (listof (cons (key anything)
(rest anything)))
msg ((initialize (nil))
(find (glambda (self key) (assoc key self)))
(insert (glambda (self key)
(cons
(send (a (typeof (first self)) with key = key)
initialize)
self)))) )
(adder (sum number)
prop ((initial-value (0)) )
msg ((init ((sum := (initial-value self))))
(update (glambda (self (item number))
((sum self) _+ item)))
(final (sum))))
Each of these components is abstract, including only the minimum information necessary to specify its own aspects of behavior. For example, alist defines the behavior of an association list in a way that matches the interface to an indexing structure used by Find-Update, but it is independent of the other information contained in an alist entry, which is specified only as (rest anything). (For simplicity, alist defines find in terms of assoc; if it were defined more generally using a generic version of assoc, type propagation would cause an appropriate comparison function to be used for keys, and the resulting code would be translatable to languages other than Lisp.) Note the use of the construction (a (typeof (first self))...) to create a new entry for the alist and initialize it [(a (typeof (first self))...) is best understood inside-out: (first self) is the first entry record of the alist, (typeof (first self)) is the type of the entry record, and (a (typeof (first self))...) creates a new record of this type. This is all evaluated at compile time; the code to extract the first element is discarded since all that is needed is its type.]: this code is abstract and will create a new instance of the application alist record and initialize it appropriately.
The components described above have been designed to be as abstract as possible, without making any unnecessary assumptions about the context of their uses. Where parameterization or features of context are needed, the abstract components use indirection, as in (a (typeof (first self))...), or send messages to themselves or to substructures. These techniques allow the components to be abstract and to be used unchanged across a variety of applications, with parameterization and glue code being concentrated in view type wrappers. This avoids the need to modify code in order to specialize procedures; in contrast, the Programmer's Apprentice project [rich81] [rich:pabook] modified code, which introduces considerable complexity. In this section, we describe view types that connect the abstract components, allowing an application to be generated by specialization.
It is useful to think of the program as existing at both an abstract level and an implementation level, with a morphism holding between the levels; this notion is formalized in SPECWARE^TM [srinivas96]. At the abstract level, Iterate-Accumulate iterates through a sequence of items, accumulating them; at the implementation level are the details of the kind of sequence, the kind of items, the aspects of items to be accumulated, the kind of accumulation, etc. The mappings between the abstract level and the implementation level are provided by view types, which provide several functions:
(myinputv (z myinput) prop ((sequence (z) result myalseq)))This view type, named myinputv, wraps the concrete input type myinput, defining the sequence as the input itself and changing its type to myalseq, whose element type will be wrapped as myalrec. The name z, which in practice is a unique generated name, is used to hide internal structure of the wrapped type to prevent name conflicts.
(myalrec (z myinputitem)
prop ((accdata ((price z)))
(key ((name z)))) )
This view type wraps the concrete item type myinputitem and
provides glue code that defines the key for indexing as the
name field of the input record and the data to be accumulated,
accdata, as the price field of the input. (The
field names name and price are used to illustrate
that the view connects the names used in the generics to arbitrary
features of the application records. Of course, computations over
several fields could be used if appropriate.)
(myview1 (z123 myaldata) prop ((sum ((data z123)))) supers (adder))This view type wraps the alist entry myaldata, defining the sum expected by an adder as the data field of that record and invoking the adder behavior by listing adder as a superclass.
An application could have multiple adders, e.g. it might be desired to accumulate both cost and weight over a list of items ordered. A separate wrapper of the data for each adder allows each to have its own sum variable in the same record.
The most complex view type is myaldata, the element of the alist, whose data structure combines an indexing field key for alist with arbitrary fields for the accumulators that are used, in this case the field data for an adder.
(myaldata (list (key symbol) (data integer))
msg ((initialize
((send (view1 self) init)
self))
(update (glambda (self item)
(send (view1 self) update (send item accdata)))))
views ((view1 adder myview1)) )
myaldata not only includes data fields for one or more
accumulators, but also redistributes messages to initialize and
update the record: to update myaldata means to update each
of its accumulators. myaldata includes a view specification:
the code (view1 self) acts as a type change function that
changes the type from myaldata to the view type myview1
that makes the record look like an adder. The update
method of myaldata redistributes the update message to
the adder view of itself using the property accdata of
the (wrapped) item as the addend.
The complete set of types for this problem includes two given types (the input list type and the element type of the list) and seven (handwritten) view types. Given these, the GLISP compiler specializes and combines five generic components (Iterate-Accumulate, Find-Update, list-iterator, alist, and adder) to produce the function shown in Fig. fig2. Except for minor differences that could be removed by an optimizer, this is the same as the hand-written function.
(LAMBDA (INPUT ACC)
(LET (ITEM ITER)
(SETQ ACC (LIST))
(SETQ ITER INPUT)
(WHILE ITER (SETQ ITEM (POP ITER))
(SETQ ACC
(LET (ENTRY)
(SETQ ENTRY (ASSOC (CAR ITEM) ACC))
(UNLESS ENTRY
(PUSH
(LET ((SELF (LIST (CAR ITEM)
0)))
(SETF (CADR SELF) 0) SELF)
ACC)
(SETQ ENTRY
(ASSOC (CAR ITEM) ACC)))
(INCF (CADR ENTRY) (CADR ITEM))
ACC)))
ACC))
Fig. 2: Result of Specialization
We have identified the abstract components of this application program and have shown how separate, independent abstract components can be combined by a compilation process using view types to produce essentially the same program as was written by a human programmer. The abstract components are satisfying in the sense that each represents a single programming concept in a clear way without any dependence on the particulars of an application. This method of breaking the program into abstract components satisfies the substitution test: it is possible to substitute or modify individual components, resulting in a correspondingly modified generated program.
We argue that real programs are based on the use of multiple views of data, and indeed, that multiple views of actual objects as different kinds of abstractions are common in design problems of all kinds. Commonly used methods of type parameterization fail to support multiple views and therefore inhibit composition of abstract components. For example, a class library may allow the user to create a class ``linked-list of t'', where t is an application type, and to obtain standard linked-list functions for this class. However, it will not be possible in general to view the resulting linked-list element as a member of a different class and inherit its methods, much less to say ``think of a linked list of cities as representing a polygon.'' With standard class parameterization, the user can obtain some procedures needed for an application by reuse, but cannot compose abstract components. Nearly all applications require composition of abstract components: as we have seen, even our small example program involved five components.
Unfortunately, the relationships of program components are complex. (We find that composition of program components is difficult for students in a freshman course for CS majors using Scheme. Some students seem to be unable to learn to do it; they say, ``I understand all the parts for this problem, but I just can't put them all together.'') The different type fonts used in the human-coded version of the example show that the abstract components of the application become thoroughly intertwined when they are translated into code. The seven view types needed for our example also are intricately related, though less so than the code itself. If a human must specify all of the view types manually in order to synthesize a program, it may be almost as easy to write the code manually. Clearly there is a need for automated tools to help synthesize the view types.
The primary abstraction mechanisms available in conventional programming are:
The structure of the view types needed for an abstract procedure such as Iterate-Accumulate can be represented abstractly as a network showing relationships among the types. These relationships provide constraints that can be used to infer some parts of the view types and can be used to guide the system in helping the user to specify others.
We have assigned graduate students to create program modules using the web-based Automatic Programming Server (APS) and VIP tools. Despite some (justified) complaints about the user interface, the students have been able to use the tools effectively to create program components. These tools satisfy our three criteria listed earlier:
Despite the success of our existing tools, these tools produce software components, not whole programs. The programmer must design data structures and the architecture of the whole system, and some code must be written by hand. It should be possible to use tools that are similarly easy-to-use to create and maintain complete programs. In this section, we discuss experimental systems we have implemented, criteria for useful programming systems, and plans for future systems.
An important criterion is that reusable components must be abstract. One method of abstraction [srinivas96] [smith90] is to start from purely mathematical components such as sets that become specialized into data structures, with operations being specialized into algorithms; this approach is well-suited to problems that are naturally described in such terms, e.g. combinatoric search problems. Our approach is to develop an ``engineering catalog'' of components that can be combined to create programs. We have demonstrated, using hand-written view types, that a single generic Iterate-Accumulate procedure can be specialized into a variety of different programs, including summing a list of numbers, making a histogram of SAT scores, numerically integrating a function, counting occurrences of words in a text file, etc. However, the view types required are complex; it seems unreasonable to require a human to create them.
As in other kinds of engineering, software components constrain each other in a variety of ways; conventional languages represent only a few of these constraints (primarily type checking). By representing constraints among components explicitly, we hope that the system can both ensure the validity of the resulting code and reduce the amount of specification required from the programmer. Our use of constraints is quite different from standard constraint satisfaction problems (CSP) [russell-norvig]. In classical CSP, the goal is to find a set of variable values that satisfies a pre-existing set of constraints. SPECWARE^TM [srinivas96] uses colimits of categories to combine specifications, resulting in combinations that satisfy all the constraints of the combined components. We envision a system in which the specification of a program will be constructed incrementally, e.g. by selecting a program framework such as Iterate-Accumulate, selecting components to plug in to that framework, such as an adder, and creating interface glue code, e.g. selecting a field from the input record to be accumulated. In this model of program construction, the set of constraints is incomplete until the end. Often, a constraint violation represents a problem waiting to be solved rather than inconsistency of previously made choices, e.g. a type mismatch may be solved by insertion of glue code that produces the needed type.
Our use of constraints is more like that in MOLGEN [stefik81] or Waltz filtering [waltz75], in which constraints and connections of components are used to propagate facts through a network representation of the problem. In one system we have constructed, called boxes, the abstract program Iterate-Accumulate is initially represented as a network containing an iterator whose output is connected to an accumulator. The input to Iterate-Accumulate is connected to the input of the iterator; however, each of these connections can be mediated by some glue code that extracts the desired data, converts data to the proper type, or performs some computation. When the user specifies some part of the specification, e.g. a data type, the specification is treated as an event on a box (a network node). An event causes rules associated with the class of the box to be examined to see if their preconditions are satisfied; if so, the rule fires, making conclusions that cause subsequent events. These rule firings have the effect of making common default decisions and propagating them through the network; when the defaults are correct, this reduces the amount the user must specify.
As an example, suppose that the user specifies the Iterate-Accumulate program framework, and then declares that its input type is (arrayof integer). This event causes this type to be matched against the abstract type of the Iterator, (sequence anything); the two types match, so the input is assumed to be directly connected to the iterator, and the iterator's input type becomes known as (arrayof integer). This event triggers a rule in the iterator, allowing it to infer its item type, integer. This is propagated to the accumulator as its input type. Since the most common way of accumulating integers is to add them, a rule fires that causes the accumulator to specialize itself to an integer accumulator. Now the output type of the accumulator is integer, which becomes the program result type.
If the user says no more, inference from this minimal specification is enough to allow a program to be generated:
result type: INTEGER(LAMBDA (IFA) (LET (ACC) (SETQ ACC 0) (LET (ITEM) (DOTIMES (INDX (ARRAY-TOTAL-SIZE IFA)) (SETQ ITEM (AREF IFA INDX)) (INCF ACC ITEM))) ACC))
However, inferences made by the system must be defeasible: it is possible that the user does not want to sum integers, but instead wants to create a histogram of the odd integers. Whenever a fact is added to the network by inference, justifications are added to identify the premises on which the inference depended. This reason maintenance allows automatic retraction of inferences made by the system (e.g. when assumptions made by rules are over-ridden by user specifications), causing inferences that depended on retracted information to be withdrawn and re-derived based on the new information. In our example, the user can add a predicate to the iterator (e.g. to select odd integers only), perform a computation on the item of the iteration (e.g., square the integers) before input to the accumulator, change the accumulator (e.g. to a histogram), parameterize the accumulator (e.g. specify the bin width of the histogram), etc.
Human-to-human communication is characterized by omission of all information that an intelligent listener should be able to infer from what was already said. In automating programming, minimizing communication of the program specification is an essential goal: one should have to tell the computer no more than one would tell a colleague to describe the same problem. We envision a programming system in which inference is used to minimize what the human must specify, allowing obvious choices to be made automatically and presenting intelligent possibilities when choices must be made. Graphical representations such as the one used by VIP can be easier to understand and manipulate than text; at the same time, large network representations are unreadable, so careful design of the interface is necessary.
Real programs are subject to maintenance (usually specification changes). We envision the network representations as being editable; view types are derived from the network, and these types allow code to be compiled by specialization of generic procedures.
This paper has analyzed a human-written program to reveal that it is composed of several abstract components that became closely interwoven in the code. We showed that a similar program could be composed from independent abstract software components using view types. Finally, we described how inference on a network representation can allow appropriate view types to be constructed from a minimal specification.
Krueger [krueger92] is an excellent survey of software reuse, with criteria for practical effectiveness. Mili [mili95] extensively surveys reuse, emphasizing technical challenges. Genesereth [genesereth94] and Wiederhold [wiederhold92] present views of advanced forms of programming.
Lowry [lowry87] discusses reformulation by abstracting from a user's program specification to an abstract specification, then using the abstract specification to generate code.
Kiczales [kiczales97] describes Aspect-Oriented Programming, in which program aspects that cross-cut the procedural structure of programs (such as performance, memory management, synchronization, and failure handling) need to be co-composed with the procedural description. An aspect weaver transforms the procedural program at join points according to specifications in a separate aspect language. Although the aspect weaver is automatic, the programmer must ensure that it will find the appropriate join points so that the program will be transformed as desired.
SPECWARE^TM [srinivas96] is a collection of tools, based on category theory, that performs composition of types by finding the colimit of the descriptions. Sorts (types) can be described by axioms in logic. The tools provided by SPECWARE could be useful in implementing the kinds of type manipulations we have described.
Biggerstaff [biggerstaff99] has developed an Anticipatory Optimization Generator, in which tags are used to control the application of program transformations. Tags are somewhat like interrupts in that they can trigger specific optimizations when likely opportunities for them arise, allowing powerful transformation of code without large search spaces.
The clich'es and overlays used in the Programmer's Apprentice [rich:pabook] [rich81] are somewhat analogous to our generics. Batory [batory93] has described construction of software systems from layers of plug-compatible components with standardized interfaces. Goguen [goguen86] proposed a library interconnection language using views in a way analogous to ours. C++ [stroustrup] allows template libraries for commonly used data structures.
Current work in automatic programming includes SciNapse [akers97], which generates programs to simulate spatial differential equations. SIGMA [keller94] constructs scientific programs from graphical specifications, somewhat like our VIP system [novak:caia94]. KIDS [smith90] transforms problem statements in first-order logic into programs that are highly efficient for certain combinatorial problems; it has a sophisticated user interface. AMPHION [lowry94] uses proofs in first-order predicate calculus to correctly combine subroutines for calculations in solar system kinematics based on a less complex user specification.
[akers97] R. Akers, E. Kant, C. Randall, S. Steinberg, and R. Young, ``SciNapse: A Problem-Solving Environment for Partial Differential Equations,'' IEEE Computational Science and Engineering, vol. 4, no. 3, July-Sept. 1997, pp 32-42.
[batory93] D. Batory, V. Singhal, J. Thomas, and M. Sirkin, ``Scalable Software Libraries,'' Proc. ACM SIGSOFT '93: Foundations of Software Engineering, Dec. 1993.
[biggerstaff99] T. Biggerstaff, ``A New Control Structure for Transformation-Based Generators,'' Proc. Int. Conf. on Software Reuse, Vienna, Austria, June, 2000, Springer-Verlag.
[gamma95] E. Gamma, R. Helm, R. Johnson, and J. Vlissides, Design Patterns: Elements of Reusable Object-Oriented Software, Addison-Wesley, 1995.
[genesereth94] M. Genesereth and S. Ketchpel, ``Software Agents,'' Communications of the ACM, vol. 37, no. 7 (Jul. 1994), pp. 48-53.
[goguen86] J. A. Goguen, ``Reusing and Interconnecting Software Components,'' IEEE Computer, pp. 16-28, Feb. 1986.
[jones93] Neil D. Jones, Carsten K. Gomard, and Peter Sestoft, Partial Evaluation and Automatic Program Generation, Prentice Hall, 1993.
[keller94] Richard M. Keller, Michal Rimon, and Aseem Das, ``A Knowledge-based Prototyping Environment for Construction of Scientific Modeling Software,'' Automated Software Engineering, vol. 1, no. 1, March 1994, pp. 79-128.
[kiczales97] Gregor Kiczales, et al., "Aspect-Oriented Programming," Proc. Euro. Conf. OOP 1997, LNCS 1241, Springer Verlag, 1997.
[knuth:vol3] D. E. Knuth, The Art of Computer Programming, vol. 3: Sorting and Searching, Addison-Wesley, 1973.
[krueger92] C. W. Krueger, ``Software Reuse,'' ACM Computing Surveys, vol. 24, no. 2, pp. 131-184, June 1992.
[lowry87] Michael R. Lowry, ``The Abstraction/Implementation Model of Problem Reformulation,'' Proc. IJCAI-87, pp. 1004-1010, 1987.
[lowry94] Michael Lowry, Andrew Philpot, Thomas Pressburger, and Ian Underwood, ``A Formal Approach to Domain-Oriented Software Design Environments,'' Proc. Ninth Knowledge-Based Software Engineering Conference (KBSE-94), pp. 48-57, 1994.
[mcilroy68] M. D. McIlroy, ``Mass-produced software components,'' in Software Engineering Concepts and Techniques, 1968 NATO Conf. Software Eng., ed. J. M. Buxton, P. Naur, and B. Randell, pp. 88-98, 1976.
[mili95] H. Mili, F. Mili, and A. Mili, ``Reusing Software: Issues and Research Directions,'' IEEE Trans. Soft. Engr., vol. 21, no. 6, pp. 528-562, June 1995.
[novak:glisp] G. Novak, ``GLISP: A LISP-Based Programming System With Data Abstraction,'' AI Magazine, vol. 4, no. 3, pp. 37-47, Fall 1983.
[novak:caia94] G. Novak, ``Generating Programs from Connections of Physical Models,'' 10th Conf. on Artificial Intelligence for Applications, IEEE CS Press, 1994, pp. 224-230.
[novak:kbse94] G. Novak, ``Composing Reusable Software Components through Views'', 9th Knowledge-Based Soft. Engr. Conf., IEEE CS Press, 1994, pp. 39-47.
[novak:units95] G. Novak, ``Conversion of Units of Measurement,'' IEEE Trans. Software Engineering, vol. 21, no. 8, pp. 651-661, Aug. 1995.
[novak:tose95] G. Novak, ``Creation of Views for Reuse of Software with Different Data Representations'', IEEE Trans. Soft. Engr., vol. 21, no. 12, pp. 993-1005, Dec. 1995.
[novak:tose97] G. Novak, ``Software Reuse by Specialization of Generic Procedures through Views, IEEE Trans. Soft. Engr., vol. 23, no. 7, pp. 401-417, July 1997.
[perry99] D. E. Perry, ``Some Holes in the Emperor's Reused Clothes,'' Proc. Ninth Annual Workshop on Software Reuse, Austin, TX, Jan. 1999.
[rich81] C. Rich, ``A Formal Representation for Plans in the Programmer's Apprentice,'' 7th Intl. Joint Conf. Art. Int. (IJCAI-81), pp. 1044-1052, 1981.
[rich:pabook] C. Rich and R. Waters, The Programmer's Apprentice, ACM Press, 1990.
[russell-norvig] S. Russell and P. Norvig, Artificial Intelligence: A Modern Approach, Prentice Hall, 1995.
[smith90] D. R. Smith, ``KIDS: A Semiautomatic Program Development System,'' IEEE Trans. Software Engineering, vol. 16, no. 9, pp. 1024-1043, Sept. 1990.
[srinivas96] Y. V. Srinivas and J. L. McDonald, ``The Architecture of SPECWARE^TM, a Formal Software Development System,'' Tech. Report KES.U.96.7, Kestrel Institute, Palo Alto, CA.
[stefik81] M. Stefik, ``Planning with Constraints (MOLGEN: Part 1),'' Artificial Intelligence, vol. 16, no. 2, May 1981.
[stroustrup] B. Stroustrup, The C++ Programming Language, Addison-Wesley, 1991.
[waltz75] D. Waltz, ``Understanding line drawings of scenes with shadows,'' in P. H. Winston, ed., The Psychology of Computer Vision, McGraw-Hill, 1975.
[wiederhold92] G. Wiederhold, P. Wegner, and S. Ceri, ``Toward Megaprogramming,'' Communications of the ACM, vol. 35, no. 11 (Nov. 1992), pp. 89-99.