TEXPLORE: Real-Time Sample Efficient Reinforcement Learning
Todd Hester
My research is focused on Reinforcement Learning (RL), a method for agents to learn to perform sequential decision making tasks through interaction with their environment. I'm focused on applying RL to more real-world problems, particularly learning on robots. Enabling robots to learn will make them generally more useful, as they will not require pre-programming for every task and environment.
In RL, an agent is in some state in the world (e.g. a particular chess board configuration or a location in a city) and has some set of actions it can take (e.g. chess moves, turns at an intersection). Upon taking an action, it reaches a new state, and receives a scalar reward (e.g. +1 for winning the chess game, -1 for losing, and 0 otherwise; or minus the time each road segment took). The goal of the agent is to learn which action to take in each state to maximize its reward over time.
There are a number of issues with applying RL to real-world problems such as robots. First, learning must happen with a limited number of actions. Methods that take thousands or millions of actions to learn are not feasible for a robot, as the robot is likely to break, wear out, run out of battery power, or overheat before that many actions can be taken. Second, learning must take place in real-time. We would like the RL agent to be in continual control of the robot, not controlling it for short periods of time followed by long pauses for it to compute what action it should take next. Finally, there are issues with handling the continuous state space of robots, and dealing with the delays many mechanical actuators have.
To address these issues, we have developed an algorithm called TEXPLORE. It is a model-based RL algorithm, which means it learns a model of the state transition and reward dynamics of the domain and then uses its model to plan a policy, enabling it to learn in fewer actions than many model-free approaches. It also utilizes a real-time architecture which performs the model learning and planning in parallel threads, so the agent can act in real-time. I've released a ROS package with the TEXPLORE source code that can be easily applied to any robots running ROS:
Model Learning
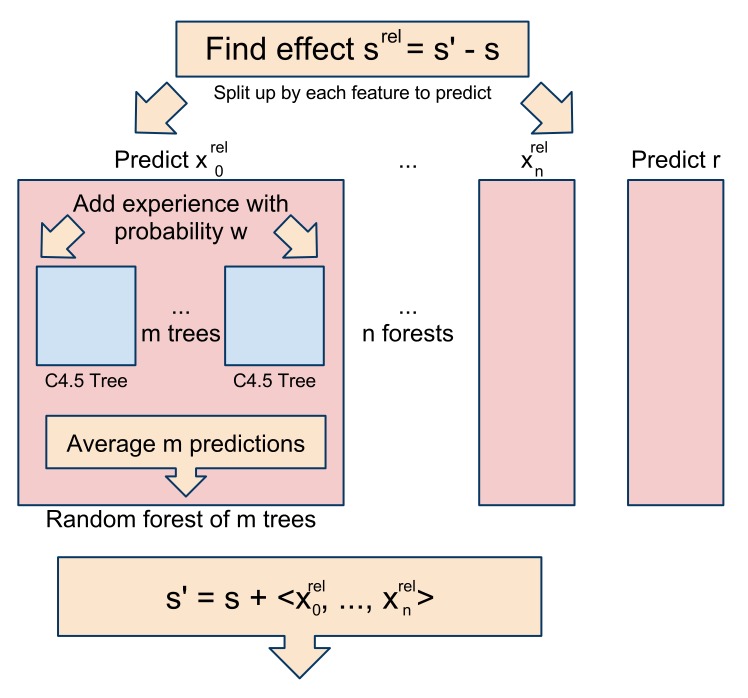
TEXPLORE is a model-based RL algorithm; it learns a model of the domain it is in. Then it can simulate actions in its model to calculate a good policy. We treat the model learning as a supervised learning problem. Given the state the agent was in and the action it took, we want to predict the next state it will get to and the reward it will receive. Every time the agent takes an action, we can use this new experience as a training sample for a supervised learning method. Using supervised learning enables the algorithm to generalize the effects of actions across states (e.g. moving the knight has the same effect no matter where some particular pawn is). With this generalization, it can make predictions about states and actions that it has never seen before.
The particular supervised learning technique we use is random forests of decision trees. The decision trees perform well because they split the state space up into regions with similar dynamics. A random forest is a set of these decision trees, each trained on a random subset of the data, and with some randomness added into their selection of tree splits. Random forests are more accurate than individual decision trees and their performance is only dependent on the number of relevant inputs rather than the total number of inputs. Each tree in the random forest represents a possible hypothesis of the true dynamics of the domain, and a comparison between these various trees can be used to drive exploration to where the trees disagree. The predictions of each tree in the forest are combined by giving each tree equal weight. For example, if 8 trees predict outcome A and 2 trees predict outcome B, then outcome A has a probability of 0.8.
Video: TEXPLORE's Random Forest Model Learning
This video demonstrates how TEXPLORE learns random forest models of the transition and reward dynamics of the domain.
Relevant Papers:
- T. Hester and P. Stone. Real Time Targeted Exploration in Large Domains. In IEEE International Conference on Development and Learning (ICDL), August, 2010. (PDF)
Real-Time Architecture
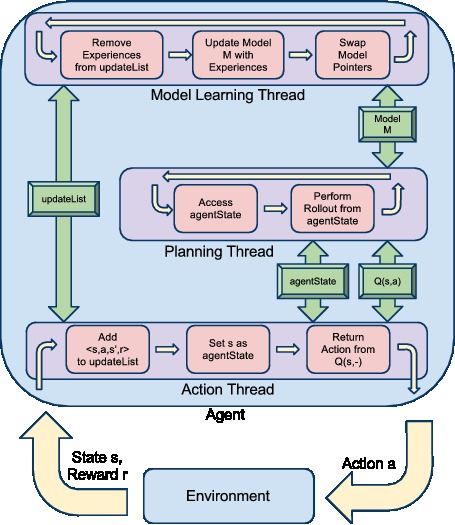
One of the goals of this research is to apply RL to robots. This often requires the RL algorithm to select actions in real-time. For example, a robotic car does not have time to stop and plan what to do next when the car in front of it slams on its brakes. The RL agent must continue to act in real-time.
Towards this goal, we have developed a real-time parallel architecture for model-based RL. The model learning and planning, both of which could take significant computation time, occur in parallel threads in the background. Meanwhile, a third thread returns the best action from the agent's current policy. This action thread is no longer constrained by the time required by the model learning and planning and can return an action immediately whenever required.
We have tested this algorithm on the task of controlling the velocity of an autonomous vehicle. Here, the agent controls the brake and accelerator pedals of the car, and is rewarded for driving at the correct speed. The car requires the agent to provide commands to the pedals at 20 Hz, otherwise it leaves the pedals in their current positions. Learning from scratch, the agent learns to control the car in less than two minutes of driving time.
Video: RTMBA Learning to Drive an Autonomous Vehicle
This video demonstrates TEXPLORE using the Real-Time Model Based RL Architecture (RTMBA) to learn to control the velocity of an autonomous vehicle in real-time by moving the brake and accelerator pedals. In just two minutes of driving time, the agent learns to accelerate the car to and maintain the desired velocity.
Relevant Papers:
- T. Hester, M. Quinlan, and P. Stone. RTMBA: A Real-Time Model-Based Reinforcement Learning Architecture for Robot Control. In IEEE International Conference on Robotics and Automation (ICRA), May, 2012. (PDF)
Exploration
One of the key problems for RL is exploration. The agent must explore sufficiently to learn enough about the world to perform well. On the other hand, it also must perform well at the task at some point, rather than continuing to explore forever. This exploration-exploitation trade-off is a difficult one.
One common approach is to explore randomly by taking the best action most of the time, and taking a random action some of the time. Model-based methods can do better than this approach by using their model to plan multi-step exploration trajectories. A common approach is to provide internal rewards for the agent to visit every state-action a number of times. By exploring every state-action, the agent guarantees that it does not miss anything and that it will learn an optimal policy. However, this exhaustive exploration is not feasible for learning quickly or on large problems.
In our work, we are focused on applying RL to real-world problems such as robots. These problems are typically large enough that is not feasible to explore exhaustively to guarantee an optimal policy. Instead, we want to explore enough to find a reasonable policy quickly. We have taken a variety of approaches to this exploration problem, which are explained in more detail below.
Target Threshold
In this approach, the user sets a minimum threshold for the value of the policy the agent should learn. Typically, this threshold is set lower than the value of the optimal policy (if that is even known). The agent will exhaustively explore every state-action in the domain until it has a policy with a value greater than or equal to the threshold. At this point, the agent stops exploring and simply follows its learned policy.
This approach has had good success on a number of different domains. One particular domain we tested it on was learning to score penalty kicks using the Aldebaran Nao robot. The video below shows the Nao robot learning to score penalty kicks, both in simulation and on the real robot.
Video: Learning to Score Penalty Kicks via Reinforcement Learning
The accompanying video for our ICRA 2010 paper, where our learning algorithm controls the robot, learning to score penalty kicks.
Relevant Papers:
- T. Hester, M. Quinlan, and P. Stone. Generalized Model Learning for Reinforcement Learning on a Humanoid Robot. In IEEE International Conference on Robotics and Automation (ICRA), May 2010. (PDF) (Video)
- T. Hester and P. Stone. Generalized Model Learning for Reinforcement Learning in Factored Domains In The Eighth International Joint Conference on Autonomous Agents and Multiagent Systems (AAMAS), May 2009. (PDF)
Random Forests
Another exploration approach is to take advantage of the different decision tree models within the random forest. Each decision tree model represents a different hypothesis of the true dynamics of the world. Some of these models are likely to predict things to be better than they are, and some will predict things as being worse than they are. We give each of these models equal weighting and plan over the combined model. Thus, if there are five models, each one's predicted outcomes are given probability 0.2.
Planning on the combined models enables the agent to naturally trade-off between exploring and exploiting. The agent can take into account the likelihood that the positive outcomes will truly happen, by weighing the likelihood of the positive models in comparison with the remaining models. If there is one model that is predicting positive outcomes, and their value is high enough that even a small probability of them happening is better than other options, the agent will explore it. On the other hand, if one model is predicting very bad outcomes, then the agent may want to avoid exploring that state-action.
We tested this approach in a novel domain called Fuel World. In this task, the agent had to choose from a number of fuel stations with varying costs on its path to its goal. The agent had to trade off the certainty of the fuel stations it knew with the likelihoods of other fuel stations being cheaper. The video shows the agent in action over its first few episodes.
Video: Random Forest Exploration in Fuel World
This video demonstrates TEXPLORE using its random forest model to drive exploration in the Fuel World domain.
Relevant Papers:
- T. Hester and P. Stone. Real Time Targeted Exploration in Large Domains. In IEEE International Conference on Development and Learning (ICDL), August, 2010. (PDF)
Intrinsic Motivation
Our third approach to exploration is to use active learning, where the agent is actively exploring states where its model is probably incorrect. We drive the agent to explore these states through the use of intrinsic rewards. The best intrinsic rewards for driving exploration are dependent on the particular model learning approach the agent uses.
For random forest models, the model is probably incorrect when the trees within the forest make differing predictions. Thus, we give the agent an intrinsic reward to explore where the tree models disagree. However, the trees are still generalizing to many unseen states and are likely to generalize incorrectly on states far from what they were trained on. Thus, we also reward the agent for going to states that are the most different from the states the agent has seen previously.
The combination of these two intrinsic rewards enables the agent to explore sufficiently to learn an accurate model of the world, without requiring it to exhaustively explore every state-action in the domain. In fact, the agent can even intelligently explore to improve its model in domains with no external rewards.
We have applied this approach to a domain called Light World, where the agent must navigate to a key, pick it up, navigate to a lock, use the key on it, and then navigate to a door and exit. The video shows the agent exploring the Light World domain. Even without external rewards, the agent can learn a model of the domain that is accurate enough to later perform tasks.
Video: Intrinsically Motivated Exploration in Light World
This video demonstrates TEXPLORE-VANIR performing intrinsically motivated exploration in the Light World domain.
Relevant Papers:
- T. Hester and P. Stone. Intrinsically Motivated Model Learning for a Developing Curious Agent In Proceedings of the AAMAS Workshop on Adaptive Learning Agents (ALA), June 2012. (PDF)
Future Directions
There are a number of directions for future work. First, we want to apply these methods to more robot tasks. Some interesting aspects of applying it to robots include incorporating continuous actions and considering connections with policy gradient methods.
Second, we want to use these methods for lifelong learning, where the agent learns in a complex domain for a long lifetime. The agent must be intrinsically motivated to learn and explore the complex domain on its own, progressively learning more complex skills, rather than being given separately defined tasks to learn and perform.
Source Code
We have released a package (rl-texplore-ros-pkg) of reinforcement learning code for ROS. It contains an implementation of our TEXPLORE agent and our real-time architecture. In addition, it has a set of RL agents and environments, as well as a formalism for them to communicate through the use of ROS messages. A common interface is defined for agents, environments, models, and planners. Therefore, it should be easy to add new agents, or add new model learning or planning methods to the existing general model based agent. The real-time architecture should work with any model learning method that fits the defined interface. In addition, since the RL agents communicate using ROS messages, it is easy to integrate them with robots using an existing ROS architecture to perform reinforcement learning on robots.
Return to my main page.
