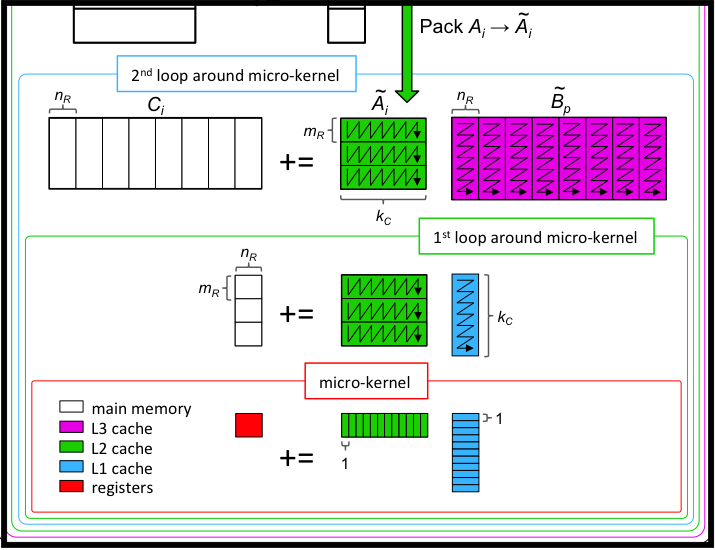
Unit 4.4.5 Richard Veras, LSU A BLIS for Stencil Computations
"In conclusion" slide (click on picture to enlarge) . For higher resolution, view the PDF.

Abstract
Stencil computations are an important class of problems that arise in a variety of fields where performance across a diverse set of architectures is critical. This includes areas ranging from physics, engineering, bioinformatics and machine learning. Thus any improvement in the efficiency of stencil computations yields increased computational productivity in those fields. Translating the regularity of a stencil into performance across SIMD vectors, multiple cores and deep memory hierarchies involves the coordination of many moving parts and requires knowledge of the target problem that may not be accessible at the compiler level. In this work we develop a systematic approach for generating high performance code for stencil kernels from the parameters of the target architecture. We then propose a BLIS-like library for stencil computations that casts high-order and high-dimensional stencil operations in terms of these generated kernels. The result is performance portable stencil computations that reach near machine peak performance. This is a work in progress.
Reference Materials:
Automating the Last-Mile for High Performance Dense Linear Algebra, R. Veras, T. M. Low, T. Smith, R. van de Geijn, F. Franchetti. ArXiv 2016.
A framework for enhancing data reuse via associative reordering, K. Stock, M. Kong, T. Grosser, LN Pouchet, F. Rastello, J. Ramanujam, P. Sadayappan. PLDI 2014.
Data layout transformation for stencil computations on short-vector simd architectures, T. Henretty, K. Stock, LN Pouchet, F. Franchetti, J. Ramanujam, P. Sadayappan. CC 2011.