
We propose projects at three levels (see figure): (1) core projects that will create an infrastructure for storing, accessing, and transporting large, heterogeneous information objects; (2) exploratory projects that will develop a variety of application-specific and general purpose languages and tools for distributed applications; and (3) realistic and ambitious applications from each of the three classes described above.
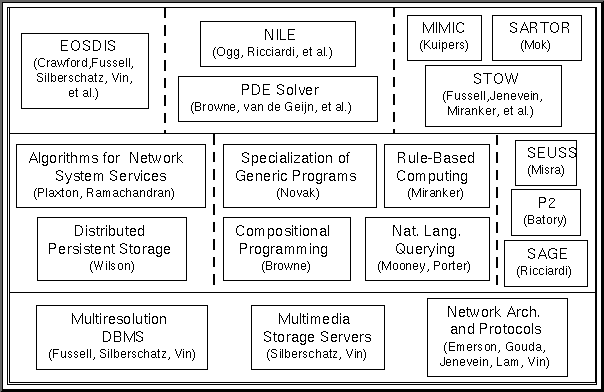
The strengths of our research include unity among the core projects, coherence among the exploratory projects, and scale of the applications. In what follows, we first describe the requirements of the applications that drive the overall research, the common theme that unites the core projects, and the extent of support technologies provided by our exploratory projects.
The goal of the UT project in support of EOSDIS is to develop a multiresolution storage and transport system for data acquired from NASA's Earth Observing System. This system must support efficient storage, retrieval and dissemination of multi-dimensional satellite imagery, along with ancillary textual and numeric metadata. The primary data is expected to reach volumes of two terabytes per day when EOSDIS becomes fully operational. Queries often involve on-line access to several terabytes of data stored across many distributed information sources. Typical queries may be difficult to express in a traditional relational query language such as SQL. In many cases, multiresolution analysis techniques will be performed on the data obtained through these queries. Thus, this application provides an ideal opportunity to develop and evaluate multiresolution databases, along with efficient and reliable storage management strategies and network protocols.
The goal of the STOW project is to develop a real-time distributed battlefield simulation comprising 10,000 combatants. Fewer than 10% of the combatants will be humans; the rest will be simulation models. The network supporting the simulation will span North America, and it must meet a stringent requirement: every object affected by a simulated action must be notified within 100 milliseconds. STOW's environmental databases include 3-D shapes and the images to be mapped onto each surface. Since graphics hardware restricts the amount of data that can be displayed in real-time, the data sent to each observer will vary in resolution. For example, an airborne observer has a distant horizon but requires little detail for the objects on the ground, while a ground-based observer has a close horizon, but requires considerable detail for objects within the horizon. The database system must support both observers with consistent data at different resolutions. Clearly, STOW's strict real-time requirement puts a premium on efficient retrieval and transmission of multiresolution objects. Moreover, the construction of a wide variety of simulated objects that meet the real-time constraints provide a significant challenge for developing large-scale software.
Our core projects, shown in the bottom layer of Figure 1, develop an integrated architecture that supports: (1) techniques for efficiently storing multimedia data on disk arrays (multimedia storage server project), (2) mechanisms for locating and accessing information objects from distributed databases (multiresolution DBMS project), and (3) protocols for providing performance guarantees to each object transmitted over the network (network architecture and protocols project). Developing an architecture that achieves the above objective will involve close interaction among the three projects on a variety of issues, including:
First, Batory's P2 system compiles lightweight database systems (LDB's). An LDB differs from a general-purpose database system in two ways: it supports only one schema with a small set of predefined retrieval and update operations, but it offers substantially better performance. LDB's are ubiquitous. Examples from our core projects include the routing table for the network manager and the lock manager for the database system, and an example from our application projects is the synthetic-environments database used in STOW. We are currently using P2 to develop a prototype of STOW's terrain database. Moreover, we plan to use it later to build the core multiresolution database system that will support STOW, and other applications, at full production levels.
Second, Wilson's TEXAS system is a persistent-storage memory manager for C++ programs. We are currently evaluating TEXAS (as an alternative to an extensible DBMS, such as POSTGRES) for prototyping our core system for storing multiresolution data. The TEXAS system falls short of our needs in one regard: it does not support distributed programs that share memory. However, Wilson's current research--which is aimed at supporting the STOW application--is addressing this problem. Wilson plans to develop the distributed persistent store using P2.
Third, Miranker's VENUS compiler for rule-based programs--which has achieved speed-ups of 2 to 3 orders of magnitude over traditional approaches for sequential rule processing--is being used to develop simulation models for STOW. Previous models for event-driven battlefield simulations were coded with imperative languages (e.g. C++, Ada). As an initial test of VENUS, Miranker reimplemented a component of a battlefield simulator used in a distributed field-artillery command and control system, and achieved adequate performance with an order of magnitude decrease in code size compared with the imperative code. Meeting the real-time requirements of class 3 applications, such as STOW, drive Miranker's current rule-technology research.
Misra's Seuss project is developing a language and methodology for multiprogramming. Two major goals of this project are: (1) to design and understand the modules (e.g., processes or data objects) of a program in isolation, without considerations of interference by the other modules, and (2) to implement the modules on separate processors with a fine grain of interleaving so that no processor is ever locked out of accessing common data for long periods of time. We are identifying components of the core systems to implement with Seuss and with conventional methods. These points of comparison will give the Seuss project important data on development time and performance.
Finally, the research by Porter and Mooney aims to improve query processing to help database users find the information they seek. Currently, query interpreters are quite rigid; even small mismatches between the terms of a query and the relations of the database can cause queries to fail. Moreover, queries must be expressed in formal languages (e.g. SQL). This research will develop methods for efficiently building the knowledge bases and natural-language parsers required for more flexible processing of database queries. This research requires large samples of realistic database queries, some of which fail due to rigidity in query processing. The applications (primarily EOSDIS) will provide this data, along with a testbed for the advanced query interpreter.
Exploiting the synergy inherent among the projects requires a management plan that focuses effort on common objectives and a shared (thus, large) computational infrastructure.