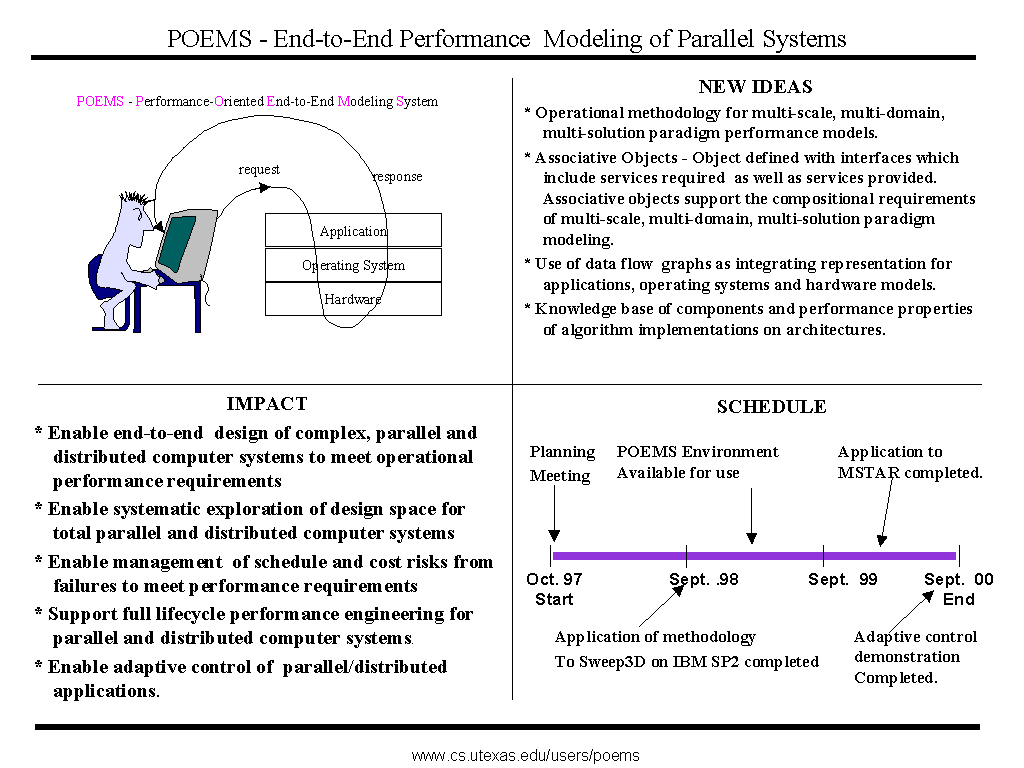
The objective for the Performance Oriented End-to-end Modeling System (POEMS) is to enable end-to-end design of complex, parallel and distributed computer systems to meet operational performance requirements and to enable management of schedule and cost risks from failures to meet performance requirements. The POEMS project will attain this objective by creating and experimentally evaluating a problem-solving environment for end-to-end performance modeling of complex parallel/distributed systems, spanning application software, runtime and operating system software, and hardware architecture. Performance engineers using POEMS should be able to construct performance models with resolution of detail ranging from early conceptual design to performance tuning of production systems. POEMS will separate specification of applications from specifications for execution environments so that each can be separately varied. POEMS targets supporting performance engineering of a total system at effort levels ranging from 1% to 10% of total system development cost.
The POEMS project combines innovations from communication models, data mediation, parallel programming, performance modeling, software engineering, and CAD/CAE. POEMS is experimentally focused and driven. The Sweep3D wavefront computational kernel has been the first driving application while a kernel from the MSTAR automatic target recognition system will be the second driving application.
The major elements of the conceptual framework of POEMS are a general model of parallel computation, the use of associative objects as the representation basis for components, the use of multiple methods of evaluation of component behavior, incorporation of a knowledge base on the behaviors of common operations on known execution environments and direct derivation of application specifications for computational kernels when they are available.
The models developed in POEMS span three domains: application, operating system, and hardware. The application domain represents parallel computation as a dynamic hierarchical task graph where nodes represent sequential computation units and edges represent dependencies. The nodes of the task graph are instances of associative objects which can be specialized to workload, software, and hardware components. Data mediation methods are used to translate the interfaces of associative objects across domains, thus enabling composition of multi-scale, multi-domain, and multi- paradigm components into a coherent system model. Each edge has associated with it a type specification, which is called a transaction.
An associative object is a "standard object" encapsulated with an associative interface. The key concepts are that objects are defined in the context of a semantic domain and that the interfaces of the objects are extended to define properties of the objects. An associative interface specifies all of the interactions in which a component can participate via two elements: an "accepts" interface for the services that it implements and a "requests" interface that specifies the services it requires. Interfaces are specified in terms of the attributes that define the behavior and the states of the standard objects. An object that has associative interfaces is said to be an associative object and an object that interacts through associative interfaces is said to have associative interactions. An associative interface is an extension of the associative model of communication to define complex dynamic interactions among object instances. For definitions of associative objects see the paper "POEMS: End-to-end Performance Design of Large Parallel Adaptive Computational Systems" which can be found on the POEMS web page.
Data-parallel compiler technology from the Rice University dHPF compiler project will be used to compute the static task graph representation for key example programs, including High Performance Fortran (HPF) as well as manually parallelized programs.
The size of the parallel/distributed systems and applications that will be analyzed by POEMS requires that analytical modeling be used as much as possible and simulation be focused on the most important regions of the design space. Simulation will also be used to validate, support, and refine the analytical models.
Analytical modeling requires parameter values that characterize task execution time and memory system/communication system resource requirements. Simulation of a single task�s execution time (which will be used both for exploring detailed memory hierarchy performance and for computing parameter values for the analytical models) requires either an executable representation of the task or its memory address trace. To meet these goals, POEMS will use a Task Execution Description (TED) to describe the modeled execution of a task. A TED is associated with each node of an application's task dependency graph. A TED contains the parametric definition of a hardware subsystem, on which the task is to execute, which is comprised of processor, memory, and transport components. In addition, a TED contains the attributes required to define the method used to model single-task execution. The methods that are being evaluated for simulating individual tasks are instruction-driven, execution-driven, and trace-driven simulation. For enhanced throughput, performance database queries will be used to compute task execution times for specific configurations of hardware subsystems. The performance database will represent a sparse matrix of recorded task execution times computed from simulations and/or system measurements.
a. The organizing methodology for end-to-end, multi-scale, multi- domain and multi-evaluation paradigm performance modeling has been developed and is being documented and evaluated.
b. The associative object concept, which is the implementation infrastructure for integration of multi-scale, multi-domain and multi- paradigm modeling, has been designed and is being implemented.
c. A scalability analysis of the Sweep3D application executing on the IBM SP2 is nearing completion. The result is a concrete prediction that the range of linear speed-up is bounded at around 1000 processors and that Sweep3D is surprisingly insensitive to granularity of communication.
d. The experimental modeling studies on Sweep3D, which are based on both execution driven simulation and analytically solvable models, have demonstrated the synergism among the different modeling paradigms and shown how the several modeling paradigms can be integrated to span broad ranges of system configurations.
e. A prototype of an analytically solvable component model for the memory system of the SGI Origin 2000 is nearing completion.
f. Several papers resulting from the POEMS project have been published. These papers can be viewed and downloaded from the POEMS web site.
g. MPI-SIM has demonstrated a 33-fold speedup of simulation time on a 64 processor SP2 for simulations of Sweep3D.
a. October 1,1998 - December 31, 1998 - Carry the experimental research on Sweep3D across multiple platforms (from the IBM SP2 to the SGI Origin) focusing on the ability to predict performance on the new platform and to build the library of component models and knowledge base which will assist in automation of total system model development.
b. October 1, 1998 - September 30, 1999 - Implement an experimentally usable version of the POEMS problem-solving environment and experimentally validate and demonstrate its use.
c. October 1, 1998 - September 30, 1999 - Apply the POEMS environment to a selected kernel of MSTAR to determine requirements for attaining operationally useful performance through parallelization.
The POEMS project is working directly with the consumers of its technology. The POEMS project includes one of its customers, LANL, as a project participant and the first application,Sweep3D, is a kernel of the ASCI program suite. This application of POEMS to Sweep3D is directly supporting the ASCI program.
The second application is MSTAR, a DARPA funded project. The MSTAR project office plans a parallel implementation for fiscal 1999 and beyond. This application of POEMS will directly support the parallelization of MSTAR.
Military command and control is becoming more and more dependent on complex software systems executing on distributed and parallel hardware system. As humans and computers are integrated into total systems the end-to-end response time of the computer portion of the system becomes a critical factor for effective total systems. But it is well established by bitter experiences that ad hoc procedures for estimating the performance of complex applications on parallel and distributed resource environments are not reliable. Additionally, failure to attain performance goals has led to costly and highly visible failures in past development programs for complex software systems. Finally, as simulations of behaviors of military systems ranging from nuclear weapons stewardship to virtual reality based combat training migrates to parallel and distributed implementations, the requirement for integration of performance engineering into the development of these systems also becomes important.
There is clearly a requirement for an effective and comprehensive capability for predicting and managing the performance behavior of complex applications on parallel and distributed resource environments throughout the lifecycle of the application system from early design through deployment and evolution.
This capability for management of performance behavior will lead to more operationally effective and cost effective implementations of application systems crucial to national security. It will reduce the risk of costly redesigns and is an essential element in effective project planning and project management.
The POEMS project addresses this requirement for system lifecycle support for effective management of end-to-end responsiveness for complex applications executing on distributed and parallel resource environments.
Return to: POEMS
homepage