
Which Digit?

Which Digit?
We also thank Daniel Urieli for the initial adaptation of this assignment for the CS343 Artificial Intelligence course at The University of Texas at Austin.
| Which Digit? |
Which Digit? |
In this project, you will design three classifiers: a perceptron classifier, a large-margin (MIRA) classifier, and a slightly modified perceptron classifier for behavioral cloning. You will test the first two classifiers on a set of scanned handwritten digit images, and the last on sets of recorded pacman games from various agents. Even with simple features, your classifiers will be able to do quite well on these tasks when given enough training data.
Optical character recognition (OCR) is the task of extracting text from image sources. The data set on which you will run your classifiers is a collection of handwritten numerical digits (0-9). This is a very commercially useful technology, similar to the technique used by the US post office to route mail by zip codes. There are systems that can perform with over 99% classification accuracy (see LeNet-5 for an example system in action).
Behavioral cloning is the task of learning to copy a behavior simply by observing examples of that behavior. In this project, you will be using this idea to mimic various pacman agents by using recorded games as training examples. Your agent will then run the classifier at each action in order to try and determine which action would be taken by the observed agent.
The code for this project contains the following files, available as a zip archive.
Data file |
|
data.zip |
Data file, including the digit and face data. |
Files you will edit |
|
naiveBayes.py |
The location where you will write your naive Bayes classifier. |
perceptron.py |
The location where you will write your perceptron classifier. |
mira.py |
The location where you will write your MIRA classifier. |
dataClassifier.py |
The wrapper code that will call your classifiers. You will also write your enhanced feature extractor here. You will also use this code to analyze the behavior of your classifier. |
Files you should read but NOT edit |
|
classificationMethod.py |
Abstract super class for the classifiers you will write.
(You should read this file carefully to see how the infrastructure is set up.) |
samples.py |
I/O code to read in the classification data. |
util.py |
Code defining some useful tools. You may be familiar with some of these by now, and they will save you a lot of time. |
mostFrequent.py |
A simple baseline classifier that just labels every instance as the most frequent class. |
What to submit: You will fill in portions of,
perceptron.py, mira.py, answers.py, perceptron_pacman.py
and dataClassifier.py
(only) during the assignment, and submit them.
This assignment should be submitted via Canvas
with the assignment name cs343-5-classification
using these submission
instructions.
Evaluation: Your code will be autograded for technical correctness. Please do not change the names of any provided functions or classes within the code, or you will wreak havoc on the autograder.
Academic Dishonesty: We will be checking your code against other submissions in the class for logical redundancy. If you copy someone else's code and submit it with minor changes, we will know. These cheat detectors are quite hard to fool, so please don't try. We trust you all to submit your own work only; please don't let us down. Instead, contact the course staff if you are having trouble.
Getting Help: You are not alone! If you find yourself stuck on something, contact the course staff for help. Office hours, and Piazza are there for your support; please use them. If you can't make our office hours, let us know and we will schedule more. We want these projects to be rewarding and instructional, not frustrating and demoralizing. But, we don't know when or how to help unless you ask. One more piece of advice: if you don't know what a variable does or what kind of values it takes, print it out.
To try out the classification pipeline, run dataClassifier.py
from the command line. This will classify the digit data using
the default classifier (mostFrequent) which blindly
classifies every example
with the most frequent label.
python dataClassifier.py
As usual, you can learn more about the possible command line options by running:
python dataClassifier.py -h
We have defined some simple features for you. Later you will
design some better features. Our simple feature set includes one
feature for
each pixel location, which can take values 0 or 1 (off or on).
The features are encoded as a Counter where keys
are feature locations (represented as (column,row)) and values
are 0 or 1. The face recognition data set has value 1 only for
those pixels identified by a Canny edge detector.
perceptron.py.
You will fill in the train function, and the findHighOddsFeatures
function.
Unlike the naive Bayes classifier, a perceptron does not use
probabilities to make its decisions. Instead, it keeps a
weight vector ![]() of each
class
of each
class ![]() (
(![]() is an identifier, not an exponent).
Given a feature list
is an identifier, not an exponent).
Given a feature list ![]() ,
the perceptron compute the class
,
the perceptron compute the class ![]() whose weight vector is most similar
to the input vector
whose weight vector is most similar
to the input vector ![]() . Formally,
given a feature vector
. Formally,
given a feature vector ![]() (in our
case, a map from pixel locations to indicators of whether they
are on), we score each class with:
(in our
case, a map from pixel locations to indicators of whether they
are on), we score each class with:

Counter.



Using the addition, subtraction, and multiplication
functionality of the
Counter class in util.py,
the perceptron updates should be
relatively easy to code. Certain implementation issues have been
taken care of for you in perceptron.py,
such as handling iterations
over the training data and ordering the update trials.
Furthermore,
the code sets up the weights data structure for
you. Each
legal label needs its own Counter full of weights.
Fill in the train
method in perceptron.py.
Run your code with:
python dataClassifier.py -c perceptron
Hints and observations:
-i iterations
option. Try different numbers of iterations and see how it
influences the performance.
In practice, you would use the performance on the validation
set to figure out
when to stop training, but you don't need to implement this
stopping criterion for
this assignment.
findHighWeightFeatures(self,
label) in perceptron.py.
It should return a list of the 100 features with highest feature
weights for that label. You can display the 100 pixels with the
largest weights using the command:
python dataClassifier.py -c perceptron -wUse this command to look at the weights, and answer the following true/false question. Which of the following sequence of weights is most representative of the perceptron?
 .
.
Answer the question answers.py in the method q2, returning either 'a' or 'b'.
mira.py. MIRA is
an online learner which is closely related to both the support
vector machine and perceptron classifiers. You will fill in the trainAndTune
function.

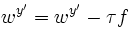
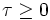 is chosen such that it
minimizes
is chosen such that it
minimizes

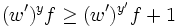
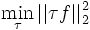 subject to
subject to  and
and 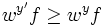 , so the
condition is always
true given Solving
this simple problem, we then have
, so the
condition is always
true given Solving
this simple problem, we then have
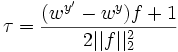
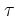 by a positive constant C, which leads us
to
by a positive constant C, which leads us
to

trainAndTune
in mira.py. This method
should train a MIRA classifier using each value of C in
Cgrid. Evaluate accuracy on the held-out validation
set for each C and choose
the C with the highest validation accuracy. In case of
ties,
prefer the lowest value of C. Test your MIRA
implementation with:
python dataClassifier.py -c mira --autotune
Hints and observations:
self.max_iterations
times during training. self.weights, so that these
weights can be used to test your classifier. --autotune
option from the command above. --autotune
should be in the 60's. Building classifiers is only a small part of getting a good system working for a task. Indeed, the main difference between a good classification system and a bad one is usually not the classifier itself (e.g. perceptron vs. naive Bayes), but rather the quality of the features used. So far, we have used the simplest possible features: the identity of each pixel (being on/off).
To increase your classifier's accuracy further, you will need
to extract more useful features from the data. The EnhancedFeatureExtractorDigit
in dataClassifier.py
is your new playground. When analyzing your classifiers'
results, you should look at some of your errors and look for
characteristics of the input that would give the classifier
useful information about the label. You can add code to the analysis
function in dataClassifier.py
to inspect what your classifier is doing.
For instance in the digit data, consider the number of separate,
connected regions of white pixels, which varies by digit type.
1, 2, 3, 5, 7 tend to have one contiguous region of white space
while the loops in 6, 8, 9 create more. The number of white
regions in a 4 depends on the writer. This is an example of a
feature that is not directly available to the classifier from
the per-pixel information. If your feature extractor adds new
features that encode these properties, the classifier will be
able exploit them. Note that some features may require
non-trivial computation to extract, so write efficient and
correct code.
Note: You will be working with digits, so make sure you are using DIGIT_DATUM_WIDTH and DIGIT_DATUM_HEIGHT, instead of FACE_DATUM_WIDTH and FACE_DATUM_HEIGHT.
EnhancedFeatureExtractorDigit
function.
Note that you can encode a feature which takes 3 values [1,2,3]
by using 3
binary features, of which only one is on at the time, to
indicate which
of the three possibilities you have. In theory, features aren't
conditionally independent as naive Bayes requires,
but your classifier can still work well in practice. We will
test your classifier with the following command:
python dataClassifier.py -d digits -c naiveBayes -f -a -t 1000With the basic features (without the
-f option),
your optimal
choice of smoothing parameter should yield 82% on the validation
set with a
test performance of 78%. You will receive 3 points for
implementing new feature(s)
which yield any improvement at all. You will receive 3 additional
points if your new feature(s) give you a test performance greater
than or equal to 84% with the above command.
You have built two different types of classifiers, a perceptron classifier and mira.
You will now use a modified version of perceptron in order to learn from pacman agents. In this question,
you will fill in the classify and train methods in perceptron_pacman.py. This code should be similar to
the methods you've written in perceptron.py.
For this application of classifiers, the data will be states, and the labels for a state will be all legal actions possible from that state. Unlike perceptron for digits, all of the labels share a single weight vector w, and the features extracted are a function of both the state and possible label.
For each action, calculate the score as follows: $$score(s, a) = w*f(s,a)$$
Then the classifier assigns whichever label receives the highest score:
$$a' = arg \max\limits_{a''} score (s,a'')$$
Training updates occur in much the same way that they do for the standard classifiers. Instead of modifying two separate weight vectors on each update, the weights for the actual and predicted labels, both updates occur on the shared weights as follows:
$$w= w+ f(s,a)$$Fill in the train method in perceptron_pacman.py. Run your code with:
python dataClassifier.py -c perceptron -d pacman
This command should yield validation and test accuracy of over 70%.
In this part you will write your own features in order to allow the classifier agent to clone the behavior of observed agents. We have provided several agents for you to try to copy behavior from:
We've placed files containing multiple recorded games for each agent in the data/pacmandata directory. Each agent has 15 games recorded and saved for training data, and 10 games for both validation and testing.
Add new features for behavioral cloning in the EnhancedPacmanFeatures function in dataClassifier.py.
Upon completing your features, you should get at least 90% accuracy on the ContestAgent, and 80% on each of the other 3 provided agents. You can directly test this using the --agentToClone <Agent name>, -g <Agent name> option for dataClassifier.py:
python dataClassifier.py -c perceptron -d pacman -f -g ContestAgent -t 1000 -s 1000
We have also provided a new ClassifierAgent, in pacmanAgents.py, for you that uses your implementation of perceptron_pacman. This agent takes in training, and optionally validation, data and performs the training step of the classifier upon initialization. Then each time it makes an action it runs the trained classifier on the state and performs the returned action. You can run this agent with the following command:
python pacman.py -p ClassifierAgent --agentArgs trainingData=<path to training data>
You can also use the --agentToClone <Agent Name> option to use one of the four agents specified above to train on:
python pacman.py -p ClassifierAgent --agentArgs agentToClone=<Agent Name>
Congratulations! You're finished with the CS 343H projects, don't forget about the contest.