CS 378 Concurrency
Lab 6
Programming Assignment:
Map Reduce Search Engine
/$ bin/hadoop jar search.jar Search hadoop export
Search Complete
3 relevant files found
Terms: hadoop, export,
hadoop-env.sh (20)
...export HADOOP_SSH_OPTS="-o ConnectTimeout=1 -o SendEnv=HADOOP_CONF_DIR"...
...export HADOOP_LOG_DIR=${HADOOP_HOME}/logs...
...export HADOOP_BALANCER_OPTS="-Dcom.sun.management.jmxremote $HADOOP_BALANCER_OPTS"...
...export HADOOP_TASKTRACKER_OPTS=...
hadoop-default.xml (5)
...Indicates how many times hadoop should attempt to contact the...
...The filesystem for Hadoop archives...
...tasks and applications using Hadoop Pipes, Hadoop Streaming etc....
...Should native hadoop libraries, if present, be used...
log4j.properties (1)
...# Sends counts of logging messages at different severity levels to Hadoop Metrics....
"operating system" http://en.wikipedia.org/wiki/Operating_system (offset 2355) http://www.webopedia.com/TERM/O/operating_system.html (offset 12) ... "semaphore" http://en.wikipedia.org/wiki/Semaphore_(programming) http://java.sun.com/j2se/1.5.0/docs/api/java/util/concurrent/Semaphore.html ... ...
Hence, when we want to search for the term "operating system", rather than reading all possible files looking for the term, we simply go to the index, see that it occurs in a number of indexed files at certain offsets from the beginning of the file, and we can return a result for the search very quickly. Of course, searching using this technique relies heavily on the ability to maintain an accurate index, so search engines have (at least) 2 main components: a component which is always indexing the web (or other searchable body) in the background, and a component which consults that index in response to search queries from users.
Another difficult problem for search engines is returning results that are actually relevant to the user's query. For example, if we search for "space pigs walking tall", we may be searching the exact phrase, or we may be searching for documents that contain some subset of these terms. In fact there may be no single document that contains all of them, so deciding whether documents about "space walking" are more relevant than documents about "tall pigs" is a difficult challenge. Perhaps we are interested in documents that contain "pig" and "walk". Consequently, search engines use elaborate heuristics (for example, Google's PageRank algorithm) to attempt to maximize the relevance of search results. These heuristics can directly influence the design of the search index.
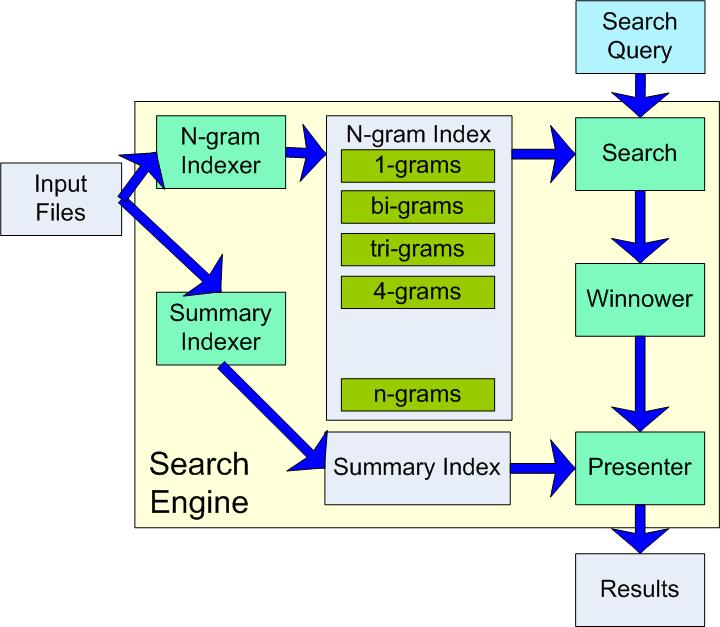
In this lab you will develop 5 Map/Reduce algorithms that address the problems of indexing, relevance, searching, and summarizing results. The general structure of our search engine is shown below.
The input files represent the body of files that our search engine searches. The search engine works by creating two different kinds of indexes. Note that these indexes only need to be created once (although you will likely need to create them many times during debugging!). After the indexes are built the search query can operate directly on them.
term file-name_0|offset_0| summary_line_0^
file-name_1|offset_1| summary_line_1^
...
file-name_n|offset_n| summary_line_n^
A term is a searchable word such as "operating", and is followed by a list of
files, offsets, and copies of the line on which the term occurred. In this
example, shown from our implementation,
volume hadoop-default.xml|16384| Reserved space in bytes per volume. Always leave this much space
waits hadoop-default.xml|24576| The time, in milliseconds, the tasktracker waits for sending a^
hadoop-default.xml|24576| The interval, in milliseconds, for which the tasktracker waits
the term "volume" occurs just once in the file "hadoop-default.xml" at byte
offset 16484, while the term "waits" occurs in two places in that same file.
The summary index is used by the Presenter
component of the search engine when writing the final search results to provide
some summary context around the search terms found: this is a simplified
version of how Internet search engines summarize the content of files when
presenting search results.
term1 term2 ... termN|file-name count
A group of N terms, separated by spaces is followed by a list of files in which
that N-gram occurs, along with a count of the the number of times the n-gram
occured in that file. In the example below:
waits |hadoop-default.xml 2
to sleep between|hadoop-default.xml 1
to sleep between|hadoop-env.sh 1
The 1-gram "waits" occurs twice in the file "hadoop-default.xml" (which we know
to be true in the summary index above as well), and the 3-gram "to sleep
between" occurs once in "hadoop-default.xml" and once in "hadoop-env.sh". NOTE:To
simplify the problem, we only count N-grams that do not cross line breaks in
the input file. The N-gram index is used by the search component of the
search engine to generate a list of candidate search matches, along with a
relevance score.
This jar file contains the Map Reduce infrastructure, a skeleton search engine program, and a searchable corpus of files. The skeleton search engine contains a version of the n-gram indexer that works for single words (1-grams) only, which you may find helpful for pattern-matching to develop the rest of your map-reduce algorithms.
To extract the lab6.jar, and create the search corpus.
$> jar -xvf lab6.jar
$> gunzip corpus.tar.gz
$> tar -xvf corpus.tar
To build the lab from the command line:
First, make sure you've got the HADOOP_HOME environment variable defined. If you are working on a linux CS machine, you can either edit the .bashrc file in your home directory to contain the line:
HADOOP_HOME=/lusr/hadoop
Or, at the command line you can type
$> export HADOOP_HOME=/lusr/hadoop
Then building is a simple matter of typing:
$> make
To invoke the search engine, navigate to the hadoop base directory and type the following at the command line:
make run
The maximum number of searchable terms is 10 by default, but this can be set by
changing Search.MAX_SEARCH_TERMS.
To use eclipse as your development environment, you need to create a project "from existing source" after you extract the jar file, the same way you did for the previous projects. However, an additional step is required to put the Hadoop libraries on your build path. To do this, you want to select "Properties" from the project menu, and choose the "Java Build Path" item in the left pane of the properties dialog. Next, select the "Add External JARS..." button, and add the following libraries. The paths shown are for CS machines:
If you are working with your own installation of hadoop, replace "/lusr/hadoop" above with whatever directory your $HADOOP_HOME variable maps to. Note that this will only get you to the point where you can build and edit your project in eclipse. You still need to run the project from the command line. To do that, read the next section!
To debug your search engine in eclipse, you need to jump through a few more hoops to make eclipse and hadoop work together. Under your Run menu, choose "Open Debug Dialog", and choose a new "Java Application" when creating a configuration. These steps should be exactly the same as for your previous projects. After this do the following:
Alternatively, you can work using eclipse with the IBM alphaWorks hadoop plug-in, which will set up these things for you, but which may introduce a number of other complications!
Search.MAX_SEARCH_TERMS defined in
Search.java. There will be a separate directory under your HDFS directory / ngram_index
for each N. For example, the bigram index is stored in ngram_index/2-grams.
The skeleton implementation we provide implements a correct indexer for
single word indexing (1-grams).
You should expand this implementation to make it possible to index N-grams.
Additionally, you can use this to pattern match and understand how to implement
your other mapper/reducer classes.
You should implement this first, since
you have some sample implementation to start from.
summary_index.
Search.run()
method, and you are responsible for filling in some of this logic. See comments
in Search.java.
Search.SHOW_RESULTS_MAX_FILES
in Search.java. The winnower also sorts the output files selected by relevance
score.
RelevantFile object), and uses the summary index
to generate the final output of the search which contains a list of relevant
files, relevance scores, and line summaries where search terms or N-grams
occur. The number of summaries shown should not exceed Presenter.MAX_RESULTS_PER_FILE.
An example of the search engine output format is shown above.
Utils.termify. If you call this method on
your search terms and terms from your searchable text, you should not have
to worry about the details of what is a legal search term. In general, the
termify method removes punctuation, changes everything to lower-case, and
requires that a searchable term either start with a letter (a-z) or be a
number. We encourage those who are interested in the nitty-gritty details to
look at the Utils.termify() method, since that is the defacto standard of what
is a legal search term for this project.
System.out.println become complicated by the fact
that such output may not be available at the command line where you invoked the
program.
System.out.println
statements go to the console where you invoked the command line. The hadoop
server running the CS machines will start by default in this mode, when you run
your code, so System.out.println will work. You can also use Utils.DEBUG(), and
Utils.info().
Also, note that because the search wants to work directly on the indexes
produced by your indexer, it checks to see if they are present in the HDFS, and
if so, skips the step of building them (that is, after all, the point of an
index). However, as you debug you may find that you need to rebuild an existing
index. You can ensure that this happens by either setting the rebuild_index
property in system.properties to true, or by using the Cleaner
class described in the next section to delete the index.
ls at the
command line, you need to go through hadoop by typing bin/hadoop fs -ls
at the command line. Similarly, to view the file of your search results,
instead of using cat search_results, you need to use bin/hadoop
fs -cat search_results/part-00000
. This takes some getting used to. In the final version of the program all
input and output goes to the console, but you may find it helpful for debugging
to be able to view files of intermediate results and for indexes.
However, When you are working on a CS machine with your hadoop server running in a standalone debug mode (the default), you can look directly at your output without going through HDFS. Your intermediate and temporary files will be in /tmp/cs378-username/ and your search results will be in your working directory in search_results/part-00000.
HDFS
Cleaner.java
. This class can be used to remove temporary files and indexes.
To remove all temporary and results files used by the search engine, type:
$HADOOP_HOME/bin/hadoop jar search.jar Cleaner
.
To remove all temporary, results, and index files, type:
$HADOOP_HOME/bin/hadoop jar search.jar Cleaner -a
You can also just use the makefile to do this by typing: 'make clean_index'.
We have provided sample correct output for the default Makefile (make run) settings in the files macbeth*.txt, which will get extracted when you unpack the jar file. The macbeth_winnow_results.txt and macbeth_search_results.txt files do not need to match exactly, and are provided to help you get a sense of what the output of intermediate search phases look like.
The following diff should yield no differences:
> make run
> diff macbeth_presentation_results myresults.txt
As with the previous labs, we will be testing your solution on other inputs, so you will need to spend some time devising other test cases and verfying that your solution works for these cases!
If you pair program, follow these additional guidelines.
In your README file, include the following:
Name
Slip days used (this project): _______ Slip days used (total): ______
On my honor, name, this programming assignment is my own work.
...if applicable...
Pair Name
Slip days used (this project): _______ Slip days used (total): ______
On our honor, name and name, this programming assignment is our own
work. We spent 80% of our time on this project together, we split the
keyboard time evenly, and we both participated equally in the solution
design.
........
Total hours spent on this project:
To turn in the project, create a tarball of your work and submit it using canvas.
Useful Links: