|
In recent years, reinforcement learning (RL) has been increasingly successful at solving complex tasks. Despite these successes, one of the fundamental challenges is that many RL methods require large amounts of experience, and thus can be slow to train in practice. Transfer learning is a recent area of research that has been shown to speed up learning on a complex task by transferring knowledge from one or more easier source tasks. Most existing transfer learning methods treat this transfer of knowledge as a one-step process, where knowledge from all the sources are directly transferred to the target. However, for complex tasks, it may be more beneficial (and even necessary) to gradually acquire skills over multiple tasks in sequence, where each subsequent task requires and builds upon knowledge gained in a previous task. This idea is pervasive throughout human learning, where people learn complex skills gradually by training via a curriculum.
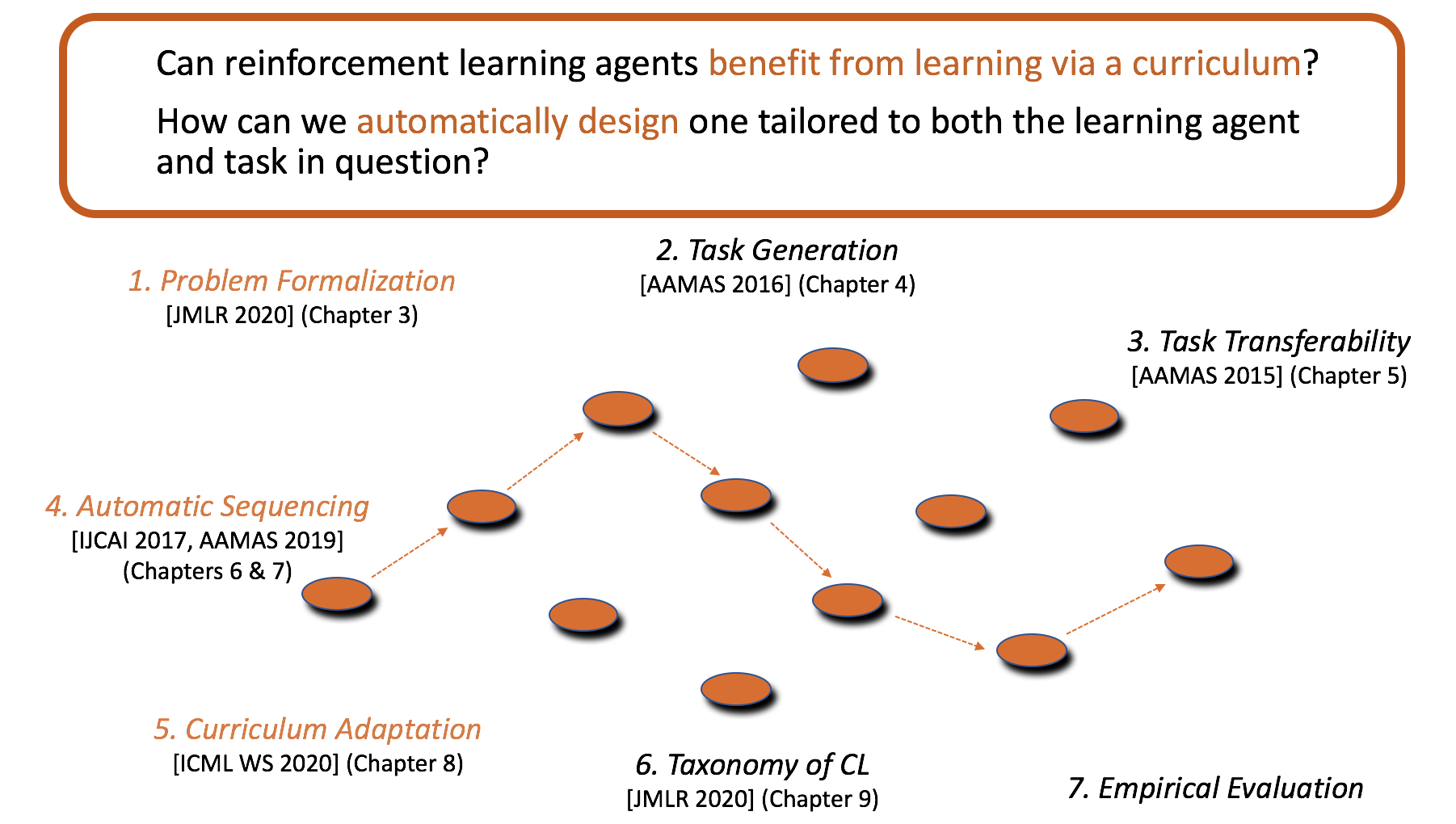
The goal of this thesis is to explore whether autonomous reinforcement learning agents can also benefit by training via a curriculum, and whether such curricula can be designed fully autonomously. In order to answer these questions, this thesis first formalizes the concept of a curriculum, and the methodology of curriculum learning in reinforcement learning. Curriculum learning consists of 3 main elements: 1) task generation, which creates a suitable set of source tasks; 2) sequencing, which focuses on how to order these tasks into a curriculum; and 3) transfer learning, which considers how to transfer knowledge between tasks in the curriculum. This thesis introduces several methods to both create suitable source tasks and automatically sequence them into a curriculum. We show that these methods produce curricula that are tailored to the individual sensing and action capabilities of different agents, and show how the curricula learned can be adapted for new, but related target tasks. Together, these methods form the components of an autonomous curriculum design agent, that can suggest a training curriculum customized to both the unique abilities of each agent and the task in question. We expect this research on the curriculum learning approach will increase the applicability and scalability of RL methods by providing a faster way of training reinforcement learning agents, compared to learning tabula rasa.
|