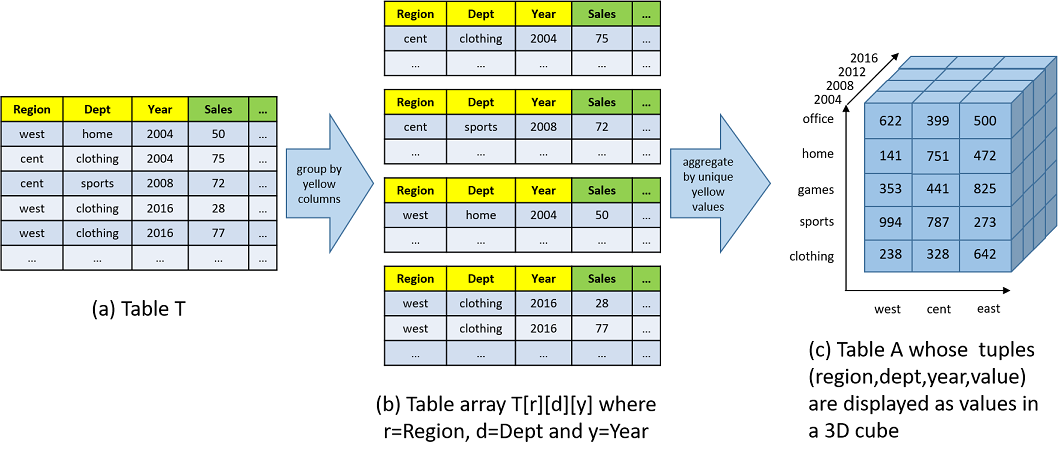
Table Aggregation in MDELite
MDELite supports a standard form of relational table aggregation that is based on the idea of relational data cubes. Start with a relational table T, Fig (a) below. A groupBy operation partitions this table into a 3D array of tables T[r][d][y], where r is a value from the Region column of T, d is a value from the Dept column of T, and y is a value from the Year column of T. All tuples t of T with Region=r, Dept=d, and Year=y are tuples of T[r][d][s].
Next, each distinct table of T[r][d][y] is aggregated into a single tuple a in table A, which has 4 columns, the groupBy columns Region, Dept, and Year and, in this case, a single aggregation value/statistic of table T[r][d][y], like what is the average of the Sales column, what is the largest value in the sales column, how many rows are there in the T[r][d][y], etc. All T[r][d][y] tables are aggregated in exactly the same manner. The resulting table A can then be aggregated, printed, etc. like the orginal table T. Some notes:
- There is no need to use groupBy -- aggergation can be performed on a single table. The result will be a table A with precisely one row.
- The number of columns in table A equals the number of groupBy columns (which could be zero), followed by the number of aggregations produced.
The basic call to group by is:
- groupBy( String[] fields,Reducer... reds ) -- where fields is an array of one or more column names, and reds is an array of reducers (a.k.a. aggregate functions).
- aggregate( Reducer... reds ) -- where reds is an array of reducers (a.k.a. aggregate functions).
The typical use of group by is:
- create the table to be "grouped"
- "groupBy" it and produce the aggregate table
- print or further aggregate the aggregate table
In the following, I present a series of aggregation and groupBy examples. The database is taken from (a database text to be specified and linked). It is complicated enough to provide a wealth of examples for aggregation (and without).
1. How many employees are from wichita?
Join the employees relation with a shortened zipcode relation and group by. One could also, in this case, just count the number of employees in the given zipcode. String[] fields = {"zipcodes.city"};
employees.join("zip", zipcodes.select(z->z.is("city","wichita")), "zip")
.groupBy(fields,new Count("cnt"))
.print();
// or
int i = zipcodes.select(z->z.is("city","wichita")).rightSemiJoin("zip",employees,"zip").count();
System.out.println("count = " + i);
2. How many versions of "Land Before Time" have been sold?
The printing of the computed relation, below, is overkill. Table t = parts.select(p->p.get("pname").startsWith("land before time"))
.rightSemiJoin("pno", odetails, "pno")
.aggregate(new IntSum("sum","qty"));
t.print();
System.out.println("Number of LBT sold = " + t.getFirst().get("sum"));
3. How many parts has each employee sold?
Table t = employees.join("eno", orders, "eno").join("orders.ono", odetails, "ono");
String[] fields = {"employees.eno","employees.ename"};
Table r = t.groupBy(fields, new IntSum("Nsold","odetails.qty"));
r.print();
4. For each part, how much money is in our warehouse?
This is a bit harder: The DoubleAgg reducer computes a field, called "money", and needs a function lambda(int i, Tuple tpl)=i + tpl.qoh*tpl*price; to compute the sum. DoubleAgg da = new DoubleAgg("money",(i,tpl) -> i + tpl.getInt("qoh")*tpl.getDouble("price"));
parts.aggregate(da).print();
5. What is the cost per order?
Table j = orders.join("ono",odetails,"ono")
.join("odetails.pno",parts,"pno");
String[] fields = {"odetails.ono"};
Table r = j.groupBy(fields,
new DoubleAgg("cost",
(d,t)-> d + t.getInt("odetails.qty")*t.getDouble("parts.price") ));
r.print();
6. What customers ordered dirty harry or dr, zhivago?
Not really an aggregation, but just for fun. parts.select(p->p.is("pname","dirty harry","dr. zhivago"))
.rightSemiJoin("pno", odetails, "pno")
.rightSemiJoin("ono", orders, "ono")
.rightSemiJoin("cno", customers, "cno")
.print();