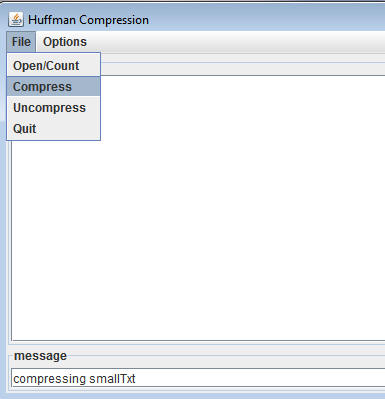
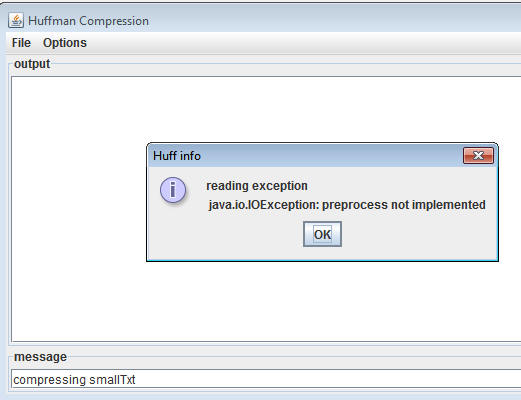
You're given classes to read and write individual bits-at-a-time. These
are described below. You're also given a main
program Huff.java that creates an instance
of the non-functioning implementation of the
IHuffProcessor
interface named SimpleHuffProcessor. Choosing options from the GUI using this implementation as shown on the
left, below, generates an error-dialog as shown on the right since none of
the methods are currently implemented (they each throw an exception).
|
|
|
When you write your methods in SimpleHuffProcessor to read
or write bits you'll need to create either a BitInputStream or a
BitOutputStream objects to read bits-at-a-time (or write
them). Information and help on how to do this is
given below, but you should probably scan this howto completely
before beginning to design and implement your solution.
BitInputStream returns an
int, so
using int variables makes sense. This means
you should refer to the BITS_PER_WORD constant from the
IHuffConstants interface and not hard code the value 8 throughout your
code. Do not use any variables of type byte in your
program. Use only int variables.int value) to Huffman codings. The map of chunk-codings
is formed by traversing the path from the root of the Huffman tree to
each leaf. Each root-to-leaf path creates a chunk-coding for the value
stored in the leaf. When going left in the tree append a zero to the
path; when going right append a one. The map has the 8-bit
int chunks as keys and the corresponding
Huffman/chunk-coding String as the value associated with the key.
The map can be an array of the appropriate size (257, due to the PSEUDO_EOF value) or you can use a Java Map instead of an array.
Once you've tested the code above (use the methods from the GUI to update and
show counts and codes!) you'll be ready to create the
compressed output file. To do this you'll read the input file a second
time, but the GUI front-end does this for you when it calls the method
IHuffProcessor.compress to do the compression. For each
8-bit chunk read, write the corresponding encoding of the 8-bit chunk
(obtained from the map of encodings) to the compressed file. You
write bits using a BitOutputStream object, you
don't write Strings/chars. Instead, the obvious thing is to write
one-bit, either a zero or a one, for each corresponding value '0' or '1' in the
string that is the encoding. Of course you may store codes in any way you
choose. They don't have to be stored in Strings and there are other approaches
besides writing a bit at a time.
Note your codes for a given file must be the same as the ones I show in sample data.
Decompressing using Huffman Coding
To uncompress the file later, you must recreate the same Huffman tree that was used to compress. This tree might be stored directly in the compressed file (e.g., using a preorder traversal, STF), or it might be created from the frequencies of the 8-bit chunk from the original file, by storing those counts or frequencies in the header (SCF). In either case, this information must be coded and transmitted along with the compressed data (the tree/count data will be stored first in the compressed file, to be read by unhuff. There's more information below on storing/reading the header information to re-create the tree.
Once the tree has been recreated start at the root of the tree and read one bit at a time from the data in the file. When a 0 is read, go left in the tree. When a 1 is read go right in the tree. After the move if the new node is a leaf node then add that value to the output file and reset the node reference to the root of the tree.
The operating system will buffer output, i.e., output to disk actually occurs when some internal buffer is full. In particular, it is not possible to write just a single bit-at-a-time to a file, all output is actually done in "chunks", e.g., it might be done in eight-bit chunks or 256-bit chunks. In any case, when you write 3 bits, then 2 bits, then 10 bits, all the bits are eventually written, but you can not be sure when they're written during the execution of your program.
Also, because of buffering, if all output is done in eight-bit
chunks and your program writes exactly 61 bits explicitly, then 3 extra
bits will be written so that the number of bits written is a multiple of
eight. Because of the potential for the existence of these "extra" bits
when reading one bit at a time, you cannot simply read bits until there
are no more left since your program might then read the extra bits
written due to buffering and add data not in the original file to the
decompressed file. This means that when reading a compressed
file, you should not use code like the loop below because
the last few bits read may not have been written by your program, but
rather as a result of buffering and writing bits in 8-bit chunks. (You don't
have to worry about when the actual writing to the file takes place other than
calling flush or close on your BitOutputStream
when you are done.)
boolean read = true;
while (read) {
int bit = input.readBits(1); // read
one bit
if (bit == -1)
read = false; // done reading, GACK
else
// process the read bit
}
To avoid this problem, there are two solutions: store the number of real bits in the header of the compressed file or use a pseudo-EOF value whose Huffman-coding is written to the compressed file. Use the pseudo-EOF technique in your program. All test cases will use the pseudo-EOF value technique. (Note, there are other possible solutions to this problem, but our specification is to use the PSEUDO_EOF value.)
When you read the compressed file your code stops when the encoding for the pseudo-EOF value is read. The pseudo code below shows how to read a compressed file using the pseudo-EOF technique. (Your actual code may vary depending on how you break up the problem.)
// read 1 bit at a time and walk tree
private int decode() throws IOException
get ready to walk tree, start at root
boolean done = false;
while(!done)
int bit =
bitsIn.readBits(1);
if(bit == -1)
throw new IOException("Error reading compressed file. \n" +
"unexpected end of input. No PSEUDO_EOF value.");
else
move left or right in tree based on value of bit
(move left if bit is 0, move right if bit is 1)
if(reached a leaf node) {
if(val is the pseudo end of file value)
done = true;
else
write out value in leaf to output
get back to root of tree
When you're writing the compressed file be sure that the last bits written are the Huffman-coding bits that correspond to the pseudo-EOF char. You will have to write these bits explicitly. These bits will be recognized and used in the decompression process. This means that your decompression program will never actually run out of bits if it's processing a properly compressed file (you may need to think about this to really believe it). In other words, when decompressing you will read bits, traverse a tree, and eventually find a leaf-node representing some value. When the pseudo-EOF leaf is found, the program can terminate because all decompression is done. If reading a bit fails because there are no more bits (the bit-reading method returns -1) the compressed file is not well formed. Your program shall cope with files that are not well-formed, be sure to test for this, i.e., test unhuff with plain (uncompressed) files.
My program generates this error when such a file is found.
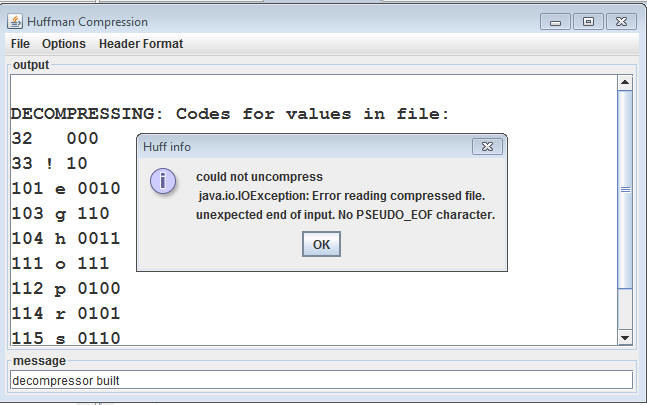
In Huffman trees/tables you use in your programs, the pseudo-EOF value/chunk always has a count of one --- this should be done explicitly in the code that determines frequency counts. In other words, a pseudo-char EOF with number of occurrences (count) of 1 must be explicitly created.
In the file
IHuffConstants
the
number of values counted is specified by ALPH_SIZE
which has value 256. Although only 256 values can be represented by
8 bits, these values are between 0 and 255, inclusive. One value is
used as the pseudo-EOF value -- it must be a value that cannot be
represented
with 8-bits, the smallest such value is 256 which requires 9 bits to
represent. However, ideally your program should be able to work with
n-bit chunks, not just 8-bit chunks. (In other words, use the constants in
IHuffConstants instead of hard coding numbers. The numbers 8, 9, 32, 255,
and 256 shouldn't appear anywhere in the code you write.)
Note, the IHuffProcessor interface extends the
IHuffConstants interface and the SimpleHuffProcessor
class implements the IHuffProcessor interface, so you have
access to the constants in IHuffConstants without constantly
writing IHuffContsants.WHAT_EVER.
You're given a TreeNode
that implements Comparable. You can use this class in
storing weighted value/chunk objects in a priority queue to make a
Huffman tree. You must write your own priority queue class because the Java
priority queue breaks ties in an arbitrary manner. (Of course you may use
pre-existing Java classes, such as lists.)
To create a table or map of coded bit values for each 8-bit chunk you'll need to traverse the Huffman tree (e.g., inorder, preorder, etc.) making an entry in the map each time you reach a leaf. For example, if you reach a leaf that stores the 8-bit chunk 'C', following a path left-left-right-right-left, then an entry in the 'C'-th location of the map should be set to 00110. You'll need to make a decision about how to store the bit patterns in the map. One option is to use a string whose only characters are '0' and '1', the string represents the path from the root of the Huffman tree to a leaf -- and the value in the leaf has a Huffman coding represented by the root-to-leaf path.
This means you'll need to follow every root-to-leaf path in the Huffman
tree, building the root-to-leaf path during the traversal. When you
reach a leaf, the path is that leaf value's encoding. One way to do this
is with a method that takes a TreeNode parameter and a
String that represents the path to the node. Initially the
string is empty "" and the node is the global root. When your code
traverses left, a "0" is added to the path, and similarly a
"1" is added when going right.
... This would be a method in the HuffmanCodeTree class and it could build a table /
map that the tree either stores or returns.
...
recurse(n.getLeft(), path + "0");
recurse(n.getRight(), path + "1");
Parts of a .hf file you must write out:
IHuffConstantsIHuffConstants
indicating if the data to rebuild the tree / codes is in Standard Count
Format (SCF) or Standard Tree Format (STF).IHuffConstantsThere are 5 steps in writing a compressed file from the
information your code determined and stored: the counts and
encodings. All this code is called from the
IHuffProcessor.compress method which is called from the GUI when
the compress option from the GUI is selected. Selecting compress results in
a call to the
IHuffProcessor.preprocessCompress method, followed by a call to the
IHuffProcessor.compress method which does the actual write to a
file.
IHuffConstants.MAGIC_NUMBER
value either without the IHuffConstants modifier in your
IHuffProcessor implementation (because the latter
interface extends the former) or using the complete
IHuffConstants.MAGIC_NUMBER identifier. When you
uncompress you'll read this number to ensure you're reading a file
your program compressed. Implement a program that can compress and uncompress
Standard Count Format first. Your program must be able to
uncompress files it creates. Your program must have
the ability to process both kinds of standard headers, specified by magic
numbers STORE_COUNTS and STORE_TREE in the
IHuffConstants interface. (Start with the simple Standard Count
Format and get that working.) There's also a value for
custom headers, but that is not used in testing or grading. (And don't use
it in your compression.). You write out the magic number as a BITS_PER_INT
int. // write out the magic number
out.writeBits(BITS_PER_INT, MAGIC_NUMBER); int magic = in.readBits(BITS_PER_INT);
if (magic != MAGIC_NUMBER) {
viewer.showError("Error reading compressed file. \n" +
"File did not
start with the huff magic number.");
return -1;
}
In general, a file with the wrong magic number should not generate an
error that halts the program, but should notify the user. For example, in my program the
exception above ultimately causes the user to see what's shown
below. This is because the exception is caught and the viewer's
showError method called appropriately. Your code should
at least print a message to the GUI, and ideally generate an error dialog as
shown.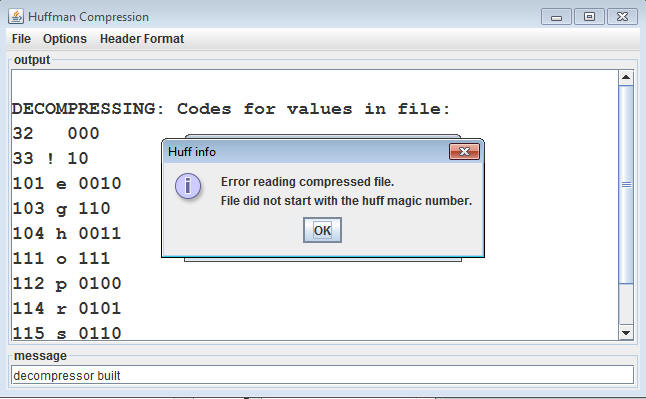
IHuffConstants indicating if the data to rebuild the tree / codes
is in Standard Count Format (SCF) or Standard Tree Format (STF).
These constants will be used by the decompressor to determine how the
format of the following data that is used to rebuild the tree in order to
decode the actual data. Recall, we are using specialized encodings that
the receiving / decompressing computer does not know, so we must provide a way to determine the
bespoke codes. You write out the header format
constant as a BITS_PER_INT int.ALPH_SIZE counts as int values (Standard Count Format), but you can also write
the tree (Standard Tree Format). Your basic compression and un-compression
code can process a header in standard count
format or SCF. This is a header of 256 (ALPH_SIZE) counts,
one 32-bit (BITS_PER_INT) int value for each 8-bit chunk, in order from 0-255.
You don't need a count for pseudo-EOF because it's always one. BITS_PER_INT is 32 in Java. We are writing out the frequencies of
the values in the original value so the decompressor can reconstruct the
tree to decode the compressed data.for(int k=0; k < IHuffConstants.ALPH_SIZE; k++) {
out.writeBits(BITS_PER_INT, myCounts[k]);
} This Standard Count Format header is read from a compressed file as follows (minus some possible error checking code), this doesn't do much, but
shows how reading/writing the header are related.
for(int k=0; k < IHuffConstants.ALPH_SIZE; k++) {
int frequencyInOriginalFile = in.readBits(BITS_PER_INT);
myCounts[k] = frequencyInOriginalFile;
}
An alternative to the count format is to write the tree instead of the counts using Standard Tree
Format. Standard Tree Format consists of one 32-bit (BITS_PER_INT)
value, an int indicating how many bits
are in the tree representation followed by the bits of the tree
as described below.
Standard Tree Format uses a 0 or 1 bit to differentiate between internal nodes and
leaves. The leaves must store values from the original file (in the
general case using (IHuffConstants.BITS_PER_WORD + 1) bits because of the pseudo-eof
value).
Standard Tree Format in the Huff program/suite uses a pre-order traversal,
a single zero-bit for internal nodes, a single one-bit for a leaf, and
nine bits for the value stored in a leaf.
Here is a VERY simple text based version of a tree and the expected bit sequence to encode the tree
...root
../....\
65.....internal node
.....
/.............\
.....32.............75
Bit representation of the above without the initial 32
bits indicating the number of bits in the tree representation. Spaces
added for clarity only.
0 1 001000001 0 1 000110010 1 001001011
For example, the sequence of 0's and 1's below represents the tree to the right(if you write the 0's and 1's the spaces wouldn't appear, the
spaces are only to make the bits more readable to humans.)
0 0 0 0 1 000100011 1 100000000 1 001000001 0 1 001010011 1 001000010 1 000100000 |
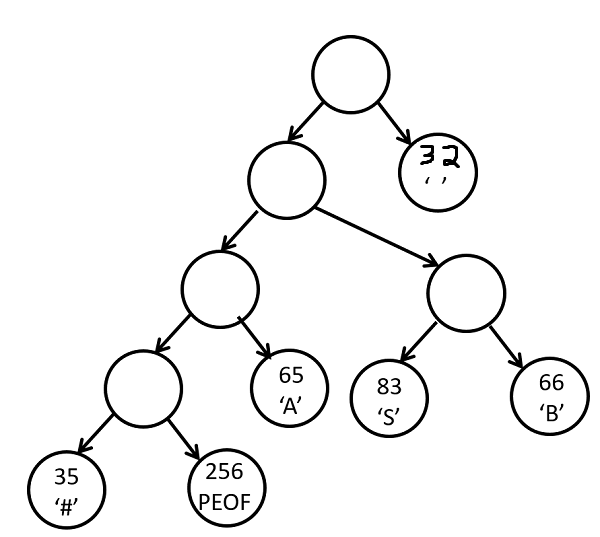 |
The first four zeros indicate internal nodes. The first 1 indicates a leaf
node that stores the value (value, not frequency) 35 which is the ASCII
value for # if we were reading a text file. The next 1 also indicates a
leaf node for the pseudo eof value which will have a value of 256. The
rest of the data indicates the other leaf nodes and the one other internal
node.
So for the example above the actual Standard Tree Format header for the tree shown above would be as
follows: (Spaces included for clarity. When written and read from a file no
spaces are present.)
00000000000000000000000001000001 0 0 0 0 1 000100011 1
100000000 1 001000001 0 1 001010011 1 001000010 1 000100000
The first value is the 32 bits for the size of the tree. The size of the tree in
bits is 65 (6 nodes with values and 11 total nodes). Write these bits using a
standard pre-order traversal.
Some algorithms for decoding the tree do not make use of this value, the
size of the tree. It is up to you.
In my code to read/write the header as a tree, the resulting header is much smaller than the standard count header.
There are other ways of getting the data the decompressor needs to rebuild the
tree, but for the assignment implement the count format and tree format as
described.
The actual compressed data. Write the bits needed to encode each value of the input
file. For example, if the coding for 'a' (or 0110 0001) is "01011" then your
code will have to write 5 bits, in the order 0, 1, 0, 1, 1 every time
the program is compressing/encoding the chunk 'a' / 0110 001 You'll re-read the
file being compressed, look up each chunk/value's encoding and
write a 0 or 1 bit for each '0' or '1' character in the encoding.
Write the code you generated for PSEUDO_EOF constant from IHuffConstants.
(Do not write the PSEUDO_EOF constant itself. Write out its code you generated
for the PSEUDO_EOF value from your Huffman Code Tree for this particular file.)
Write your own tests and see what happens with small files.
The expected frequency and codes for the small text file (Eerie eyes seen near lake.) and the 2008 CIA Factbook are useful in checking your work. The codes for the small text file are different than the example from the class slides due to the period value being inserted out of order in the slides and the presence of the PSEUDO EOF value.
You can also use the provided Diff.java class to compare two files. (it is in the HuffmanStarter.jar file) Your compressed files for the small text file and the CIA Factbook must match the provided samples created using the standard count format.. (smallText.txt.hf and ciaFactbook2008.txt.hf)
Designing debugging functions as part of the original program will
make the program development go more quickly since you will be able to
verify that pieces of the program, or certain classes, work
properly. Building in the debugging scaffolding from the start will make
it much easier to test and develop your program. When testing, use small
examples of test files maybe even as simple as "Eerie eyes seen near lake." that help
you verify that your program and classes are functioning as intended. Use the
update, showMessage, and showError
messages from the HuffViewer class to see what is going on.
You might want to write encoding bits out first as strings or printable int values rather than as raw bits of zeros and ones which won't be readable except to other computer programs. A Compress class, for example, could support printAscii functions and printBits to print in human readable or machine readable formats.
I cannot stress enough how important it is to develop your program a few steps at a time. At each step, you should have a functioning program, although it may not do everything the first time it's run. By developing in stages, you may find it easier to isolate bugs and you will be more likely to get a program working faster. In other words, do not write hundreds of lines of code before testing. Testing rocks. Debugging stinks.
BitInputStream and
BitOutputStream.
To see how the readBits routine works, consider the
following code segment. It reads BITS_PER_WORD bits at a time (which is
8 bits as defined in IHuffConstants) and echoes what is
read.
BitInputStream bits = new BitInputStream(someInputStreamObject);
// wrap the input stream I am given in a bit input stream
int inbits = bits.readBits(IHuffConstants.BITS_PER_WORD));
while ((inbits != -1) {
System.out.println(inbits); // prints the value we read in as
an int regardless of what it was suppose to represent
inbits = bits.readBits(IHuffConstants.BITS_PER_WORD));
}
Note that executing the Java statement System.out.print('7') results in
16
bits being written because a Java char
uses 16 bits (the 16 bits
correspond to the character '7'). Executing
System.out.println(7). results in 32 bits being written because a
Java int uses 32
bits. Executing obs.writeBits(3,7) results in 3 bits being
written (to the BitOutputStream obs) --- all the bits are 1
because the number 7 is represented in base two by 0000 0000 0000 0000 0000 0000 0000 0111.
(only the 3 rightmost bits are written.) When writing out constants and
counts to the compressed file use IHuffConstants.BITS_PER_INT
which is 32. When writing out the '1's and '0's from the new code for chunks
you will be writing single bits. When writing to the uncompressed file you
will be writing out IHuffConstants.BITS_PER_WORD.
When using writeBits to write a specified number of
bits, some bits may not be written immediately because of
buffering. To ensure that all bits are written, the
last bits must be explicitly flushed. The function flush
must be called either explicitly or by calling
close.
Although readBits can be called to read a single bit at a time (by setting the parameter to 1), the return value from the method is an int.
InputStream object to the model for readable-files, it will
also send an OutputStream for writeable-files. The
client/model code you write will need to wrap this stream
in an appropriate BitInputStream or
BitOutputStream object.
public int uncompress(InputStream in,
OutputStream out)
...
BitInputStream bis = new
BitInputStream(in);
...
Of course exceptions may need to be caught or rethrown. For input,
you'll need to always create a BitInputStream object to
read chunks or bits from. For the output stream, you may need to create
a BitOutputStream to write individual bits, so you should
create such a stream -- for uncompressing it's possible to just write
without creating a BitOutputStream using the
OutputStream.write method, but you'll find it simpler to use
BitOutputStream.writeBits method.
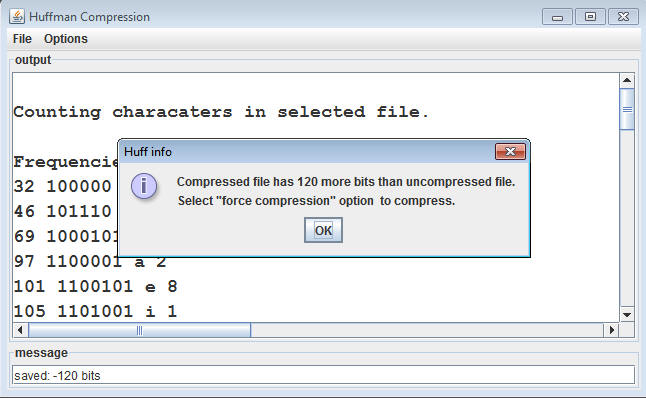
You can choose a force compression option from the GUI/Options
menu. If this is chosen/checked, the value of the third parameter to
IHuffProcessor.compress is true, and your code should
"compress" a file even though the resulting file will be
bigger. Otherwise (force is false), if the compressed file is bigger,
your program should not compress and should generate an error
such as the one shown above.
The readBits(int howMany) method from the BitInputStream
class and the writeBits(int howManyBits, int value) method from the
BitOutputStream class both have the potential to throw
IOExceptions.
IOExceptions are a standard Java exception. An
IOException indicates something "bad" or "unexpected" has happened while
trying to do input or output. There are two ways to deal with these exceptions
in your program.
Pass the buck and when reading bits, check every read to see if the value
returned is -1. The readBits method returns -1 if there were fewer
bits than requested in the stream (file) the reader was connected to. If this
occurs you code needs to stop what it is doing, show an error message via the
viewer and return. This can lead to pretty gacky code such as this (taking from
by decoder / uncompress / unhuff class):
// read 1 bit at a time and walk tree
private int decode() throws IOException {
// get ready to walk tree
boolean done = false;
while(!done) {
int bit = bitsIn.readBits(1);
if(bit == -1)
throw new
IOException("Error reading compressed file. \n" +
"unexpected end of input. No PSEUDO_EOF value.");
// let
someone else who knows more about the problem deal with it.
else
...
The code tries to read a bit and if it can't then it shows an error and stops
what it is doing. Note the method has the clause throws IOException.
This is necessary because the call the readBits method has the same
clause. IOException is a type of exception referred to as a checked exception.
This means the compiler checks to see that you are doing something about the
exception if it occurs. Checked exceptions indicate something bad has happened
that is beyond the programmers control. For example a file being removed before
we are done reading from it. The other kind of exception that you are more
familiar with are referred to as unchecked or runtime exceptions. These are
things like NullPointerException,
ArrayIndexOutOfBoundsException, and IllegalArgumentException.
These indicate a logic error on the programmers part that is entirely
preventable. The compiler does not check to see if you handle or deal
with unchecked exceptions because they are never suppose to occur.
Checked exceptions are different. The compiler wants to see you have at least
thought about the problem. In the fist case we have thought about it and decided
it is someone else's problem. In this case whoever called our method. If you
trace back to the HuffView class you will find the code that calls
the preprocessCompress, compress, and uncompress
methods has code to deal with any IOExceptions those methods throw.
When an exception is thrown the regular program logic stops and the
exception handling mechanism takes over. This is part of the runtime system. The
exception handling mechanism will back out of methods on the program stack until
it finds error handling code (a catch block) which is executed. The code does
not jump back to where the exception occurred.
The alternative to passing the buck is dealing with the exception locally via a
try - catch block. This is Java syntax that tries to execute code that
could generate a checked exception (the try block) and then has code to deal
with the exception if it occurs (the catch block).
// read 1 bit at a time and walk tree
private int decode() {
// get ready to walk tree
boolean done = false;
try {
while(!done) {
int bit =
bitsIn.readBits(1);
if(bit == -1)
{
viewer.showError("Error reading compressed file. \n" +
"unexpected end of input. No PSEUDO_EOF value.");
done = true;
result = -1;
}
...
} catch(IOException e) {
// code to deal with exception
}
The downside of this approach on this assignment is the exception should be
dealt with by the HuffViewer, so it is appropriate to pass the buck
in this case. I recommend taking the first approach on the assignment.