Adaptive Planner Parameter Learning (APPL)
Xuesu Xiao1, Garrett Warnell2, Bo Liu1, Zifan Xu1, Zizhao Wang1,Gauraang Dhamankar1, Anirudh Nair1, and Peter Stone1, 3
1 The University of Texas at Austin 2 US Army Research Laboratory 3 Sony AI
Introduction
While current autonomous navigation systems allow robots to successfully drive themselves from one point to another in specific environments, they typically require extensive manual parameter re-tuning by human robotics experts in order to function in new environments. Furthermore, even for just one complex environment, a single set of fine-tuned parameters may not work well in different regions of that environment. These problems prohibit reliable mobile robot deployment by non-expert users. Adaptive Planner Parameter Learning (APPL) is a paradigm that devises a machine learning component on top of existing navigation systems to dynamically fine-tune planner parameters during deployment to adapt to different scenarios and to achieve robust and efficient navigation performance. APPL learns from different interactions modalities from non-expert users, such as teleoperated demonstration, corrective interventions, evaluative feedback, or reinforcement learning in simulation. APPL is agnostic to the underlying navigation system and inherits benefits of classical navigation systems, such as safety and explainability, while giving classical methods the flexibility and adaptivity of learning. Our experiment results show that using APPL mobile robots can improve their navigation performance in a variety of deployment environments through continual, iterative human interaction and simulation training.
APPLD
[PDF] [Video] [Presentation] [Press]Adaptive Planner Parameter Learning from Demonstration (APPLD) learns a set of planner parameters from a full teleoperated demonstration from non-expert users. The demonstration is segmented into smaller, cohesive components, which we call contexts. For each context, we use Behavior Cloning and black box optimization to find appropriate system parameters. We also train a context predictor to recognize the context during deployment, so the corresponding parameters can be selected to be used by the underlying navigation system.
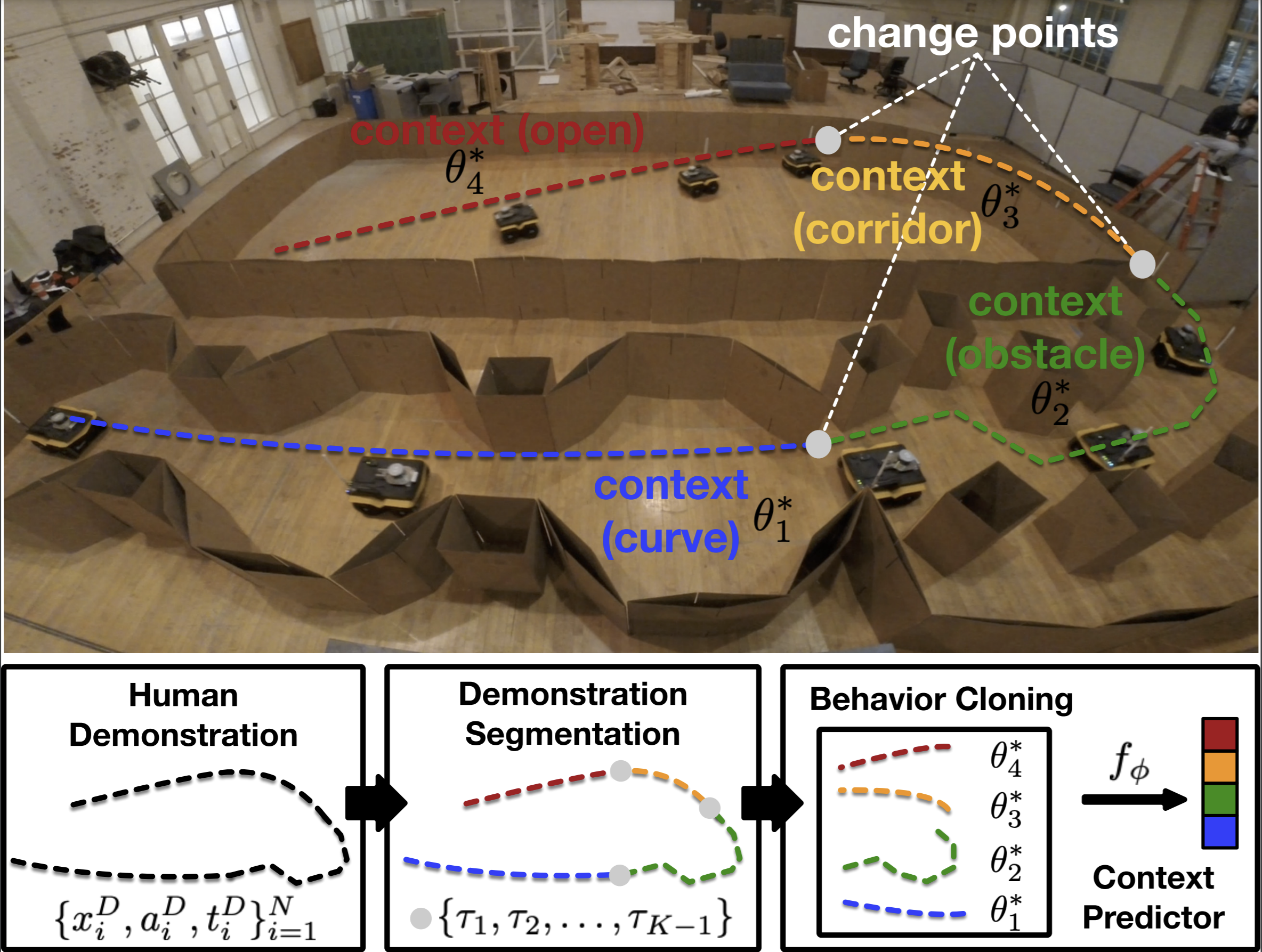
title={Appld: Adaptive planner parameter learning from demonstration},
author={Xiao, Xuesu and Liu, Bo and Warnell, Garrett and Fink, Jonathan and Stone, Peter},
journal={IEEE Robotics and Automation Letters},
volume={5},
number={3},
pages={4541--4547},
year={2020},
publisher={IEEE}
}
APPLI
[PDF] [Video]Adaptive Planner Parameter Learning from Interventions (APPLI) learns a set of planner parameters from a few corrective interventions from non-expert users. The interventions take place only when the robot fails or suffers from suboptimal behaviors at certain places (shown in red and yellow, respectively). Each intervention is treated as a standalone context, for which an appropriate set of planner parameters are learned using Behavior Cloning and black box optimization. We also train the context predictor with Evidential Deep Learning, so the context prediction is associated with a confidence measure. During deployment, when the confidence measure is low, the planner uses the default parameters.
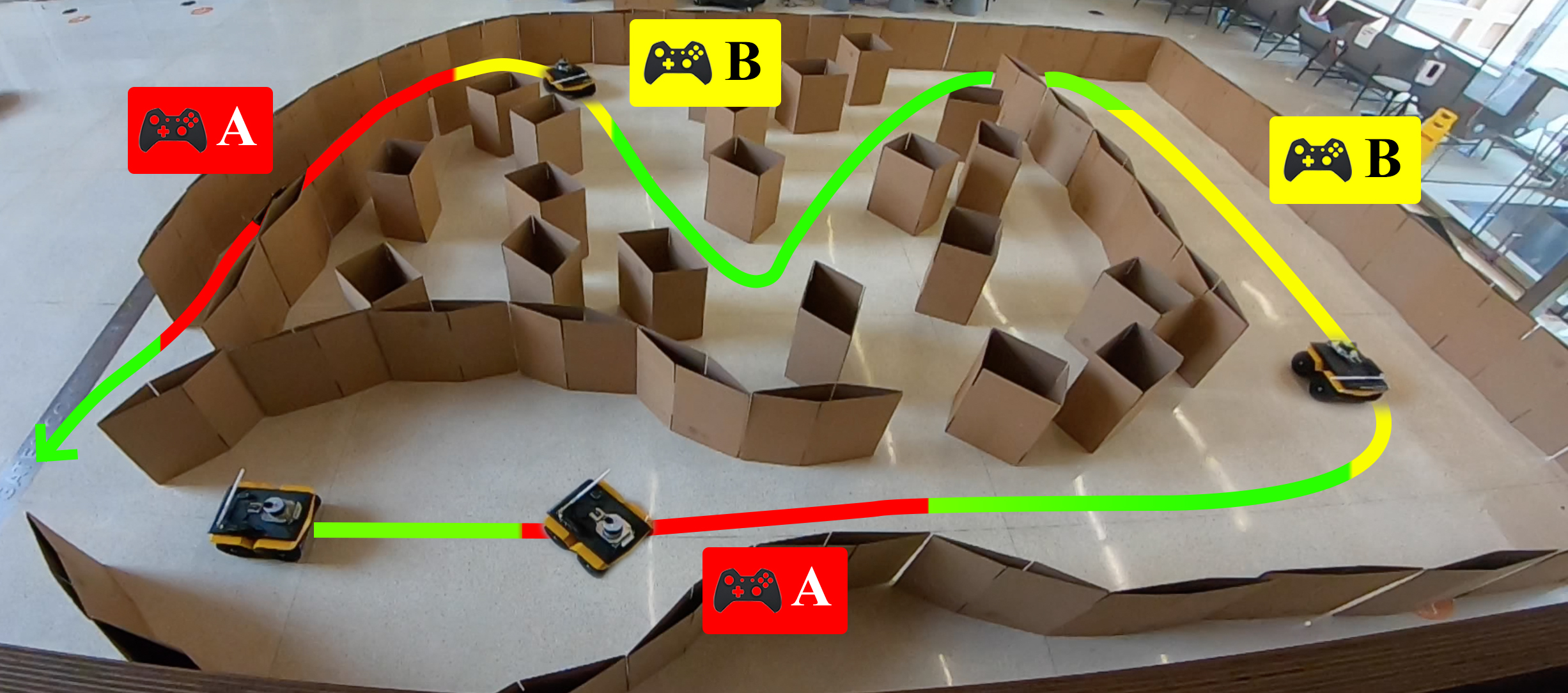
title={APPLI: Adaptive Planner Parameter Learning From Interventions},
author={Wang, Zizhao and Xiao, Xuesu and Liu, Bo and Warnell, Garrett and Stone, Peter},
booktitle = {2021 IEEE International Conference on Robotics and Automation (ICRA)},
year={2021},
organization = {IEEE}
}
APPLE
[PDF] [Video]Adaptive Planner Parameter Learning from Evaluative Feedback (APPLE) learns a parameter policy, a mapping from navigation states to appropriate planner parameters, from scalar or even binary evaluative feedback from non-expert users. The user gives positive and negative feedback based on observed navigation performance (green thumbs-up and red thumbs-down), from which the robot learns to select a parameter set that maximizes the expected user feedback during deployment.

title={APPLE: Adaptive planner parameter learning from evaluative feedback},
author={Wang, Zizhao and Xiao, Xuesu and Warnell, Garrett and Stone, Peter},
journal={IEEE Robotics and Automation Letters},
volume={6},
number={4},
pages={7744--7749},
year={2021},
publisher={IEEE}
}
APPLR
[PDF] [Video]Adaptive Planner Parameter Learning from Reinforcement (APPLR) learns a parameter policy from reinforcement in simulation. APPLR is learned in the 300 navigation environments in the Benchmark Autonomous Robot Navigation (BARN) Dataset. The APPLR agent treats the underlying classical motion planner as part of the environment in a meta Markov Decision Process (MDP), and takes its action in the parameter space, in contrast to the traditional raw motor command space. This meta MDP setup allows the benefits or classical navigation systems to be inherited and improves learning efficiency.
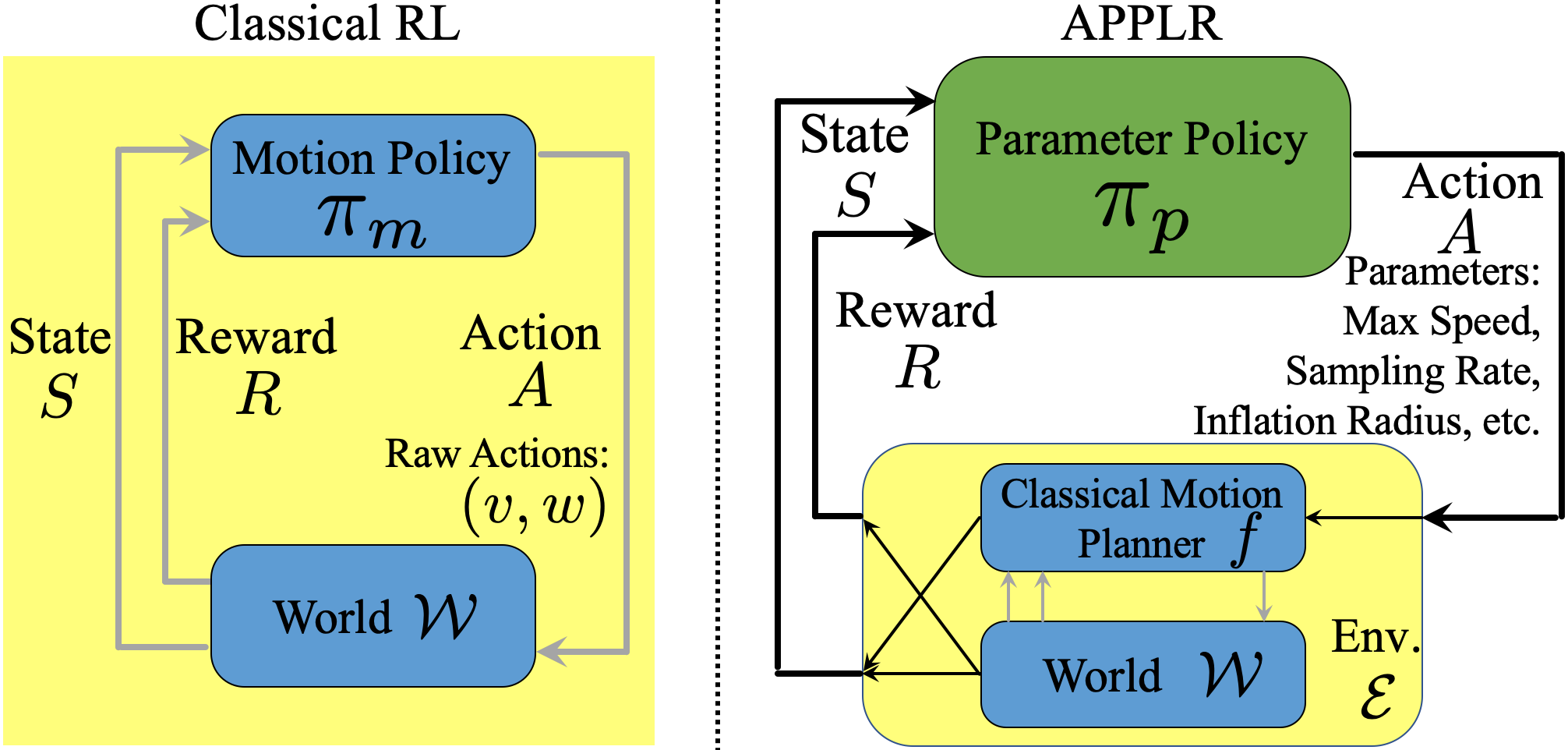
title={APPLR: Adaptive Planner Parameter Learning from Reinforcement},
author={Xu, Zifan and Dhamankar, Gauraang and Nair, Anirudh and Xiao, Xuesu and Warnell, Garrett and Liu, Bo and Wang, Zizhao and Stone, Peter},
booktitle = {2021 IEEE International Conference on Robotics and Automation (ICRA)},
year={2021},
organization = {IEEE}
}
Cycle-of-Learning
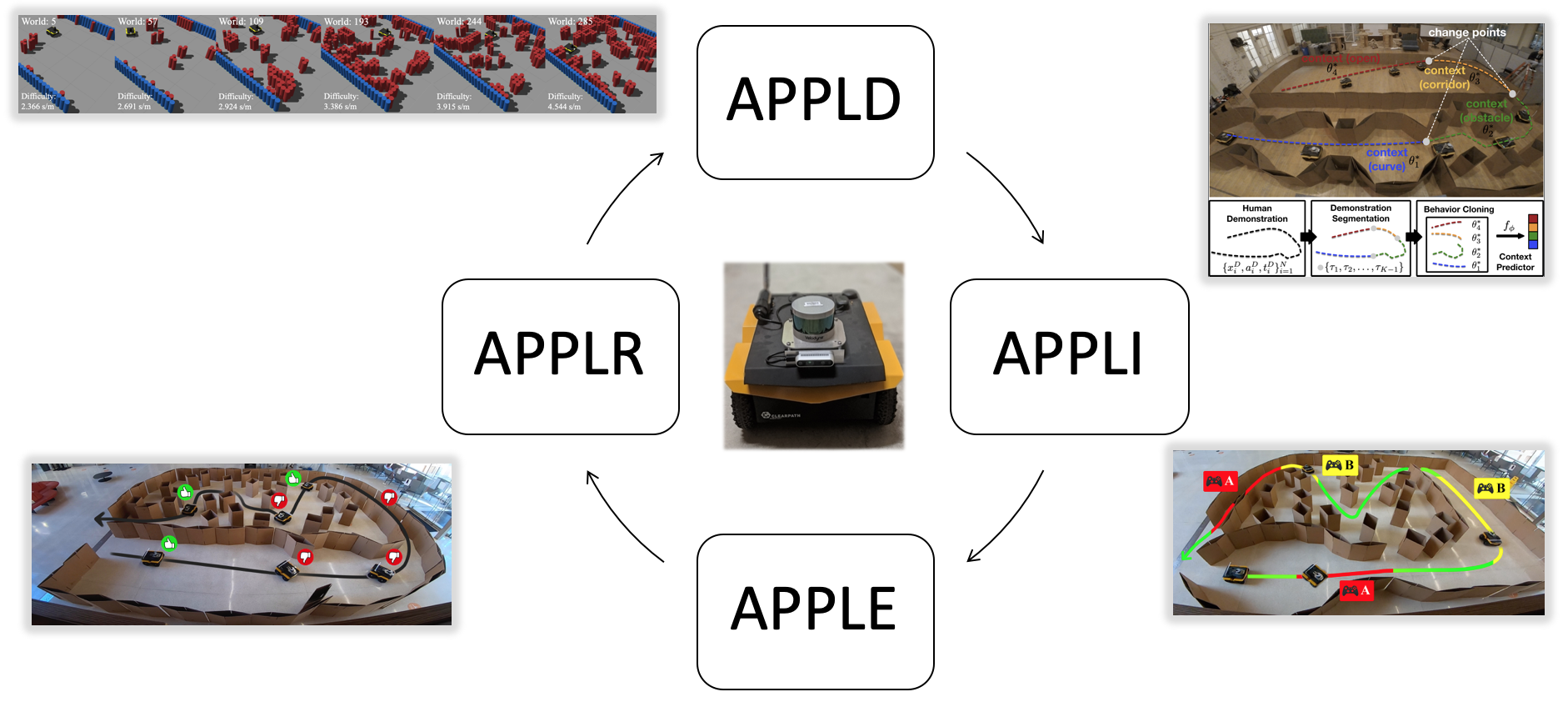
[PDF] [Video]Leveraging all APPL components, the Cycle-of-Learning scheme aims at iteratively improving the robot's navigation performance in a cyclic fashion, i.e., any interactions (demonstration, interventions, or evaluative feedback) with non-expert users and reinforcement learning in simulation do not only improve navigation performance in the current deployment, but also all future deployment.
title={APPL: Adaptive Planner Parameter Learning},
author={Xiao, Xuesu and Wang, Zizhao and Xu, Zifan and Liu, Bo and Warnell, Garrett and Dhamankar, Gauraang and Nair, Anirudh and Stone, Peter},
journal={Robotics and Autonomous Systems},
volume={154},
pages={104132},
year={2022},
publisher={Elsevier}
}
References
- X. Xiao, B. Liu, G. Warnell, J. Fink, and P. Stone. APPLD: Adaptive Planner Parameter Learning from Demonstration. IEEE Robotics and Automation Letters (RA-L), Vol. 5, No. 3: 4541-4547, July 2020.
- Z. Wang, X. Xiao, B. Liu, G. Warnell, and P. Stone. APPLI: Adaptive Planner Parameter Learning from Interventions. IEEE International Conference on Robotics and Automation (ICRA), pp. 6079-6085, June 2021.
- Z. Wang, X. Xiao, G. Warnell, and P. Stone. APPLE: Adaptive Planner Parameter Learning from Evaluative Feedback. IEEE Robotics and Automation Letters (RA-L), Vol. 6, No. 4: 7744-7749, October 2021.
- Z. Xu, G. Dhamankar, A. Nair, X. Xiao, G. Warnell, B. Liu, Z. Wang, and P. Stone. APPLR: Adaptive Planner Parameter Learning from Reinforcement. IEEE International Conference on Robotics and Automation (ICRA), pp. 6086-6092, June 2021.
- X. Xiao, Z. Wang, Z. Xu, B. Liu, G. Warnell, G. Dhanmankar, A. Nair, and P. Stone. APPL: Adaptive Planner Parameter Learning. Robotics and Autonomous Systems, 154: 104132, August 2022.
Acknowledgments
This work has taken place in the Learning Agents Research Group (LARG) at the Artificial Intelligence Laboratory, The University of Texas at Austin. LARG research is supported in part by grants from the National Science Foundation (CPS-1739964, IIS-1724157, NRI-1925082), the Office of Naval Research (N00014-18-2243), Future of Life Institute (RFP2-000), Army Research Office (W911NF-19-2-0333), DARPA, Lockheed Martin, General Motors, and Bosch. The views and conclusions contained in this document are those of the authors alone. Peter Stone serves as the Executive Director of Sony AI America and receives financial compensation for this work. The terms of this arrangement have been reviewed and approved by the University of Texas at Austin in accordance with its policy on objectivity in research.
Contact
For questions, please contact:
Dr. Xuesu Xiao
Department of Computer Science
The University of Texas at Austin
2317 Speedway, Austin, Texas 78712-1757 USA
+1 (512) 471-9765
xiao@cs.utexas.edu
https://www.cs.utexas.edu/~xiao/