
Unit 3.3.6 Micro-kernel with packed data
¶
void Gemm_MRxNRKernel_Packed( int k,
double *MP_A, double *MP_B, double *C, int ldC )
{
__m256d gamma_0123_0 = _mm256_loadu_pd( &gamma( 0,0 ) );
__m256d gamma_0123_1 = _mm256_loadu_pd( &gamma( 0,1 ) );
__m256d gamma_0123_2 = _mm256_loadu_pd( &gamma( 0,2 ) );
__m256d gamma_0123_3 = _mm256_loadu_pd( &gamma( 0,3 ) );
__m256d beta_p_j;
for ( int p=0; p<k; p++ ){
/* load alpha( 0:3, p ) */
__m256d alpha_0123_p = _mm256_loadu_pd( MP_A );
/* load beta( p, 0 ); update gamma( 0:3, 0 ) */
beta_p_j = _mm256_broadcast_sd( MP_B );
gamma_0123_0 = _mm256_fmadd_pd( alpha_0123_p, beta_p_j, gamma_0123_0 );
/* load beta( p, 1 ); update gamma( 0:3, 1 ) */
beta_p_j = _mm256_broadcast_sd( MP_B+1 );
gamma_0123_1 = _mm256_fmadd_pd( alpha_0123_p, beta_p_j, gamma_0123_1 );
/* load beta( p, 2 ); update gamma( 0:3, 2 ) */
beta_p_j = _mm256_broadcast_sd( MP_B+2 );
gamma_0123_2 = _mm256_fmadd_pd( alpha_0123_p, beta_p_j, gamma_0123_2 );
/* load beta( p, 3 ); update gamma( 0:3, 3 ) */
beta_p_j = _mm256_broadcast_sd( MP_B+3 );
gamma_0123_3 = _mm256_fmadd_pd( alpha_0123_p, beta_p_j, gamma_0123_3 );
MP_A += MR;
MP_B += NR;
}
/* Store the updated results. This should be done more carefully since
there may be an incomplete micro-tile. */
_mm256_storeu_pd( &gamma(0,0), gamma_0123_0 );
_mm256_storeu_pd( &gamma(0,1), gamma_0123_1 );
_mm256_storeu_pd( &gamma(0,2), gamma_0123_2 );
_mm256_storeu_pd( &gamma(0,3), gamma_0123_3 );
}
How to modify the five loops to incorporate packing was discussed in Unit 3.3.5. A micro-kernel to compute with the packed data when \(m_R \times n_R = 4 \times 4 \) is now illustrated in Figure 3.3.8.
Homework 3.3.6.1.
Examine the files Assignments/Week3/C/Gemm_Five_Loops_Packed_MRxNRKernel.c and Assignments/Week3/C/Gemm_4x4Kernel_Packed.c. Collect performance data with
make Five_Loops_Packed_4x4Kerneland view the resulting performance with Live Script Plot_Five_Loops.mlx.
On Robert's laptop:
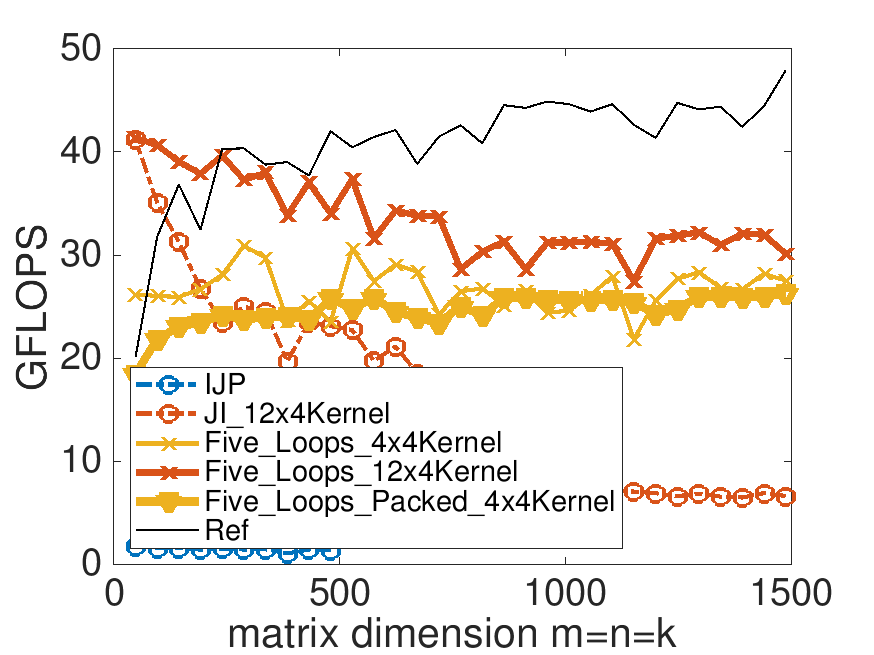
Homework 3.3.6.2.
Copy the file Gemm_4x4Kernel_Packed.c into file Gemm_12x4Kernel_Packed.c. Modify that file so that it uses \(m_R \times n_R = 12 \times 4 \text{.}\) Test the result with
make Five_Loops_Packed_12x4Kerneland view the resulting performance with Live Script Plot_Five_Loops.mlx.
Assignments/Week3/Answers/Gemm_12x4Kernel_Packed.c
On Robert's laptop:
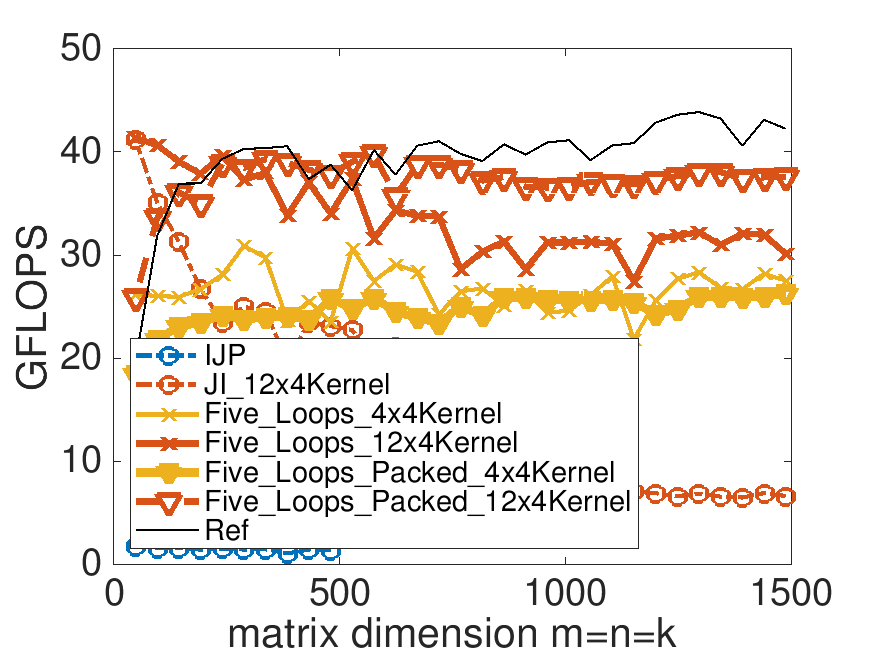
Homework 3.3.6.3.
In Homework 3.2.3.1, you determined the best block sizes MC and KC. Now that you have added packing to the implementation of the five loops around the micro-kernel, these parameters need to be revisited. You can collect data for a range of choices by executing
make Five_Loops_Packed_?x?Kernel_MCxKCwhere ?x? is your favorite choice for register blocking. View the result with data/Plot_Five_loops.mlx.