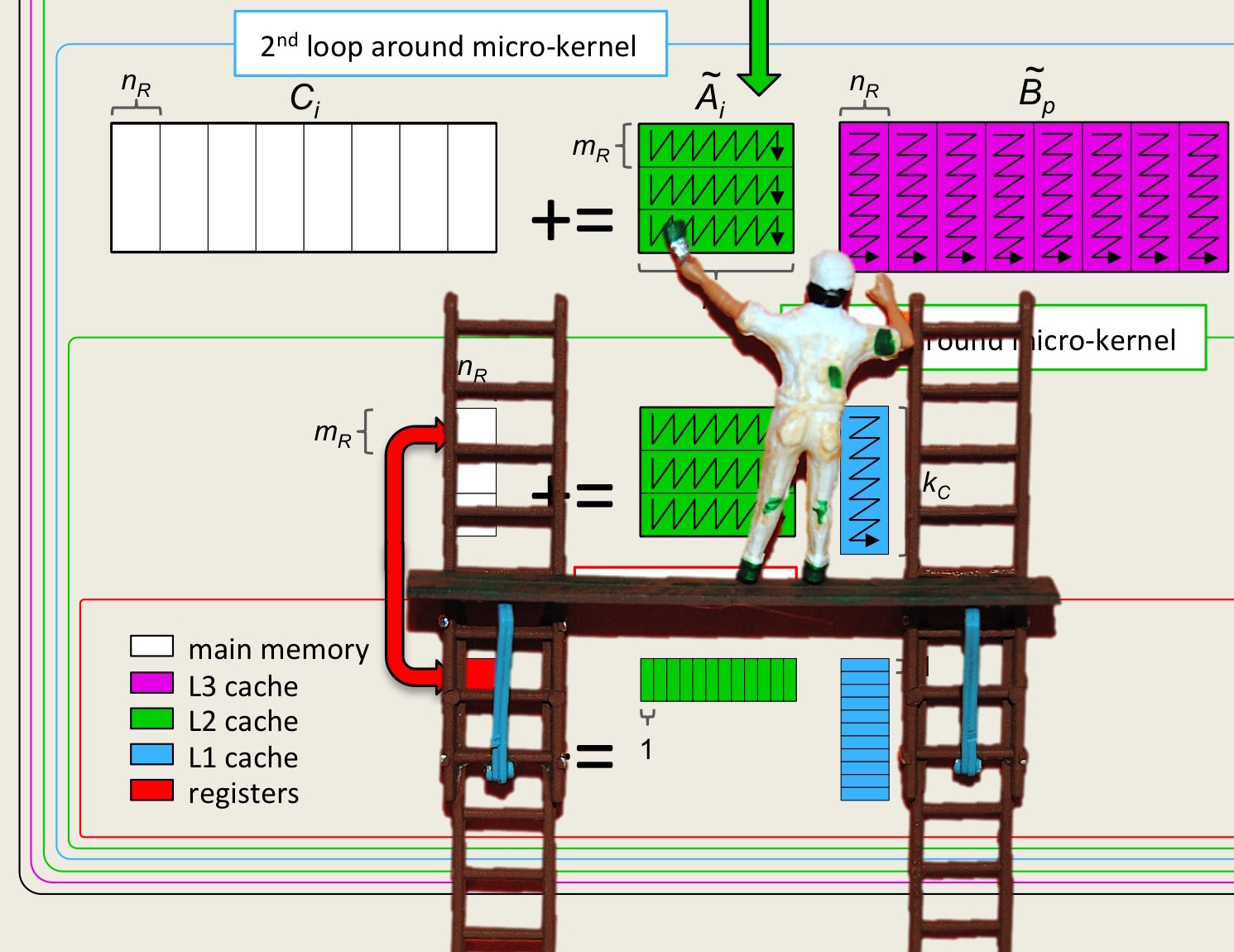
Section 3.4 Further Tricks of the Trade
¶The course so far has exposed you to the "big ideas" on how to highly optimize matrix-matrix multiplication. You may be able to apply some of these ideas (how to extract parallelism via vector instructions, the importance of reusing data, and the benefits of accessing data with stride one) to your own computations. For some computations, there is no opportunity to reuse data to that same extent, which means they are inherently bandwidth bound.
By now, you may also have discovered that this kind of programming is just not your cup of soup. What we hope you will then have realized is that there are high-performance libraries out there, and that it is important to cast your computations in terms of calls to those libraries so that you benefit from the expertise of others.
Some of you now feel "the need for speed." You enjoy understanding how software and hardware interact and you have found a passion for optimizing computation. In this section, we give a laundry list of further optimizations that can be tried by you and others like you. We merely mention the possibilities and leave it to you to research the details and translate these into even faster code. If you are taking this course as an edX MOOC, you can discuss the result with others on the discussion forum.