Token Caching for Diffusion Transformer Acceleration arxiv:2409.18523
Keywords
Diffusion models, Token Caching, Optimization, Model Acceleration
Overview
Motivation & Key Contributions
- Motivation:
- Diffusion generative models are slow because of high computational cost, arising from:
- Quadratic computational complexity of attention mechanisms
- Multi-step inference
- Diffusion generative models are slow because of high computational cost, arising from:
- How to reduce this computational bottleneck?
- Reduce redundant computations among tokens across inference steps
- Key Contributions:
- Which tokens should be pruned to eliminate redundancy?
- Which blocks should be targeted to prune the tokens?
- Which timesteps should be applied caching?
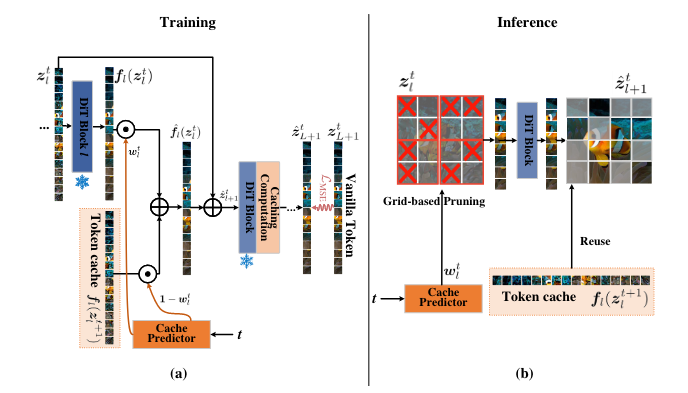
Token Cache (System Overview)
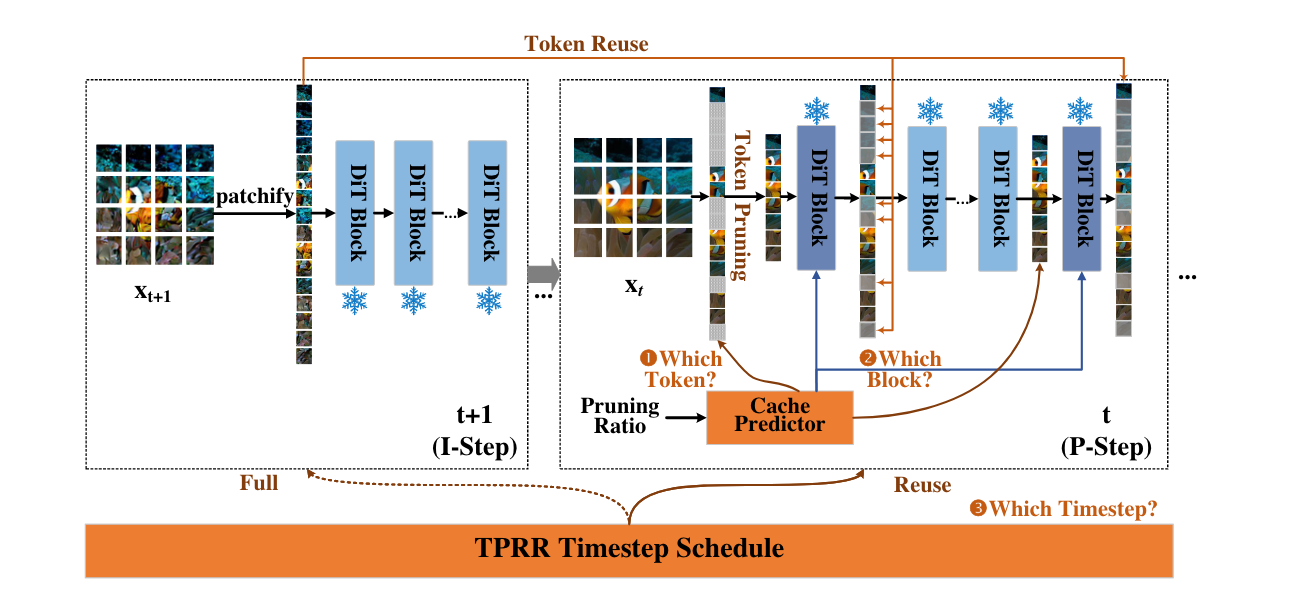
Cache Predictor (Visualized)
Two-Phase Round Robin Timestep Scheduler
Token Caching inherintly adds errors into the samplingtrajectory.
How to mitigate errors?
- Perform independent (no-cache) steps (I-Steps) after K prediction/caching steps (P-Steps)
- K = Caching Interval
How to choose K?
- Token correlations vary across timesteps.
- Higher correlations among tokens across early timesteps
- Lower correlations among tokens across later timesteps
- Token correlations vary across timesteps.
TPPR
- Phase-1 employs larger caching interval K_1
- Phase-2 employs smaller caching interval K_2
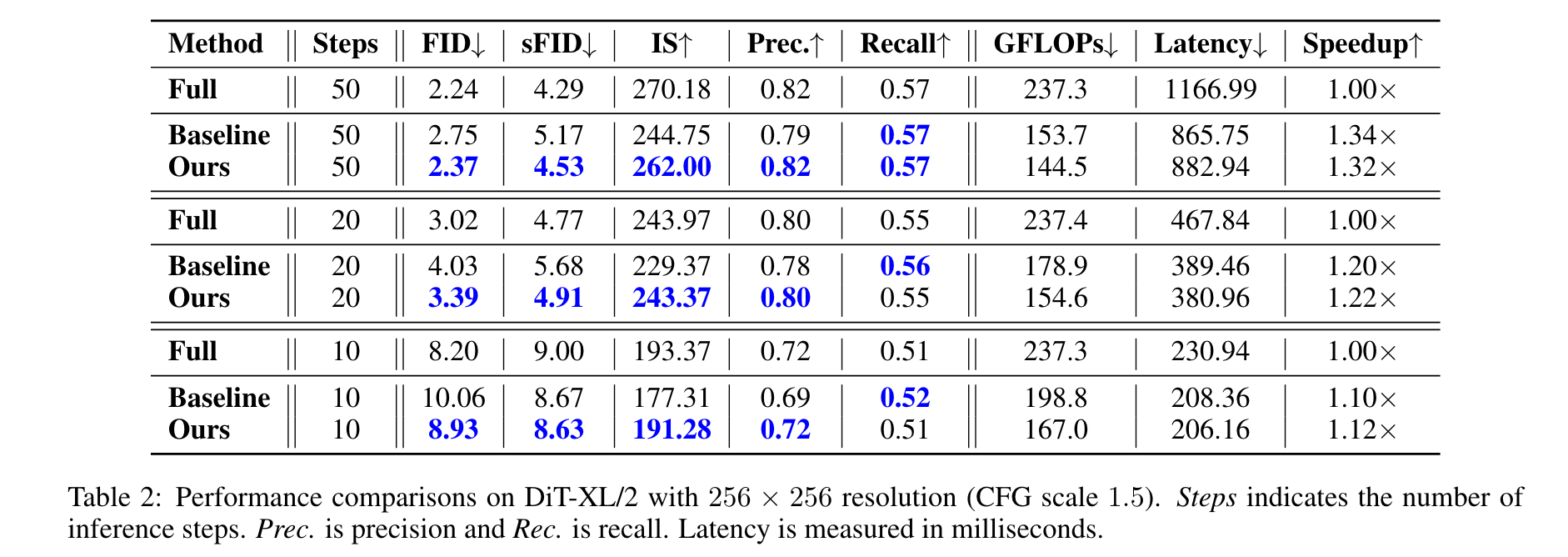
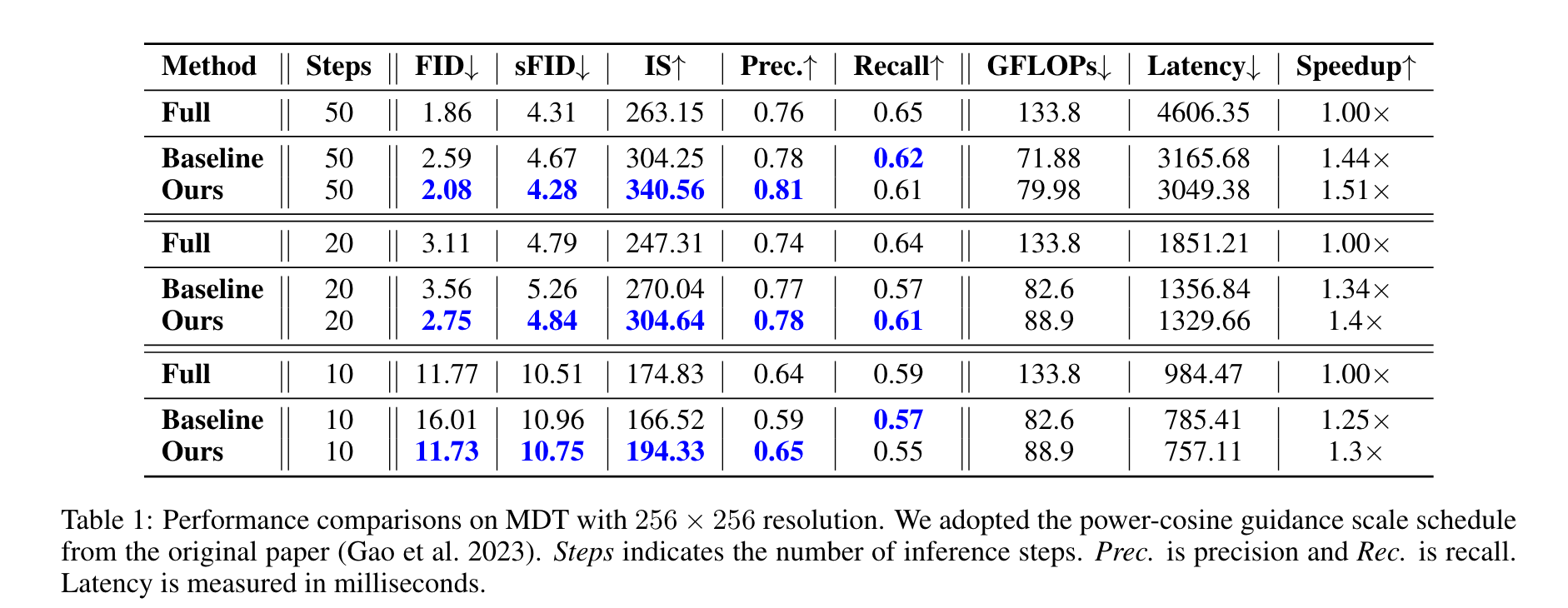
Experimental Results
References
📑 Bibliography
Lou, Jinming, Wenyang Luo, Yufan Liu, Bing Li, Xinmiao Ding, Weiming Hu, Jiajiong Cao, Yuming Li, and Chenguang Ma. 2024. “Token Caching for Diffusion Transformer Acceleration.” https://arxiv.org/abs/2409.18523.
Citation
For attribution, please cite this work as:
Muaz, Muhammad. 2024. “Personal Website.” October 16, 2024.
https://cs.utexas.edu/~mmuaz.