
Neural Networks Research Group / Department of Computer Sciences
Digital Media Collaboratory / IC2 Institute
College of Natural Sciences / The University of Texas at Austin
Introduction
NERO (which stands for Neuro-Evolving Robotic Operatives) is a new kind of machine learning game being developed at the Neural Networks Research Group, Department of Computer Sciences, University of Texas at Austin. The goals of the project are (1) to demonstrate the power of state-of-the-art machine learning technology, (2) to create an engaging game based on it, and (3) to provide a robust and challenging development and benchmarking domain for AI researchers.
Project Background
In August 2003 the Digital Media Collaboratory (DMC) of the Innovation Creativity and Capital Institute (IC2) at the University of Texas held its second GameDev conference. The focus of the 2003 conference was on artificial intelligence, and consequently the DMC invited several people from the Neural Networks Research Group at the University's Department of Computer Science (UTCS) to make presentations on academic AI research with potential game applications.
The GameDev conference also held break-out sessions where groups brainstormed ideas for innovative games. In one of these sessions, Ken Stanley came up with an idea for a game based on a real-time variant of his previously published NEAT learning algorithm. On the basis of Ken's proposal, the DMC/IC2 resolved to staff and fund a project to create a professional-quality demo of the game. (See production credits.)
The resulting NERO project started in October 2003; NERO 1.0 was released in June 2005, and NERO 1.1 in November 2005. NERO 2.0 is a major new release, including a new interactive territory mode of game play, a new user interface, and more extensive training tools (for more details about the new features, see the What's new? page).
The NERO project has resulted in several spin-off research projects in neuroevolution techniques and intelligent systems (see the project bibliography.) It is also used as the basis for an undergraduate research projects courses at UT Austin (NSC309, CS370).
The NERO Story
The NERO game takes place in the future as the player tries to outsmart an ancient AI in order to colonize a distant Earth-like planet (read the NERO story).
The NERO Game
NERO is an example of a new genre of games, called Machine Learning Games. Although it resembles some RTS games, there are three important differences: (1) in NERO the agents are embedded in a 3D physics simulation, (2) the agents are trainable, and (3) the game consists of two distinct phases of play. In the first phase individual players deploy agents, i.e. simulated robots, in a "sandbox" and train them to the desired tactical doctrine. Once a collection of robots has been trained, a second phase of play (either battle or territory mode) allows players to pit their robots in a battle against robots trained by some other player, to see how effective their training was. The training phase is the most innovative aspect of game play in NERO, and is also the most interesting from the perspective of AI research.
Training Phase
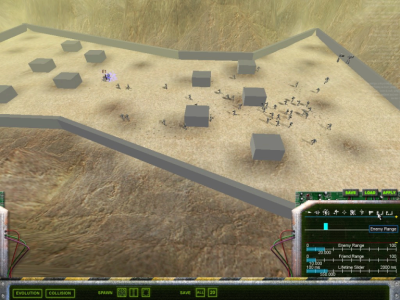
Screenshot of the NERO game in training mode.
In NERO the player needs to train robots to battle other robots, in order to colonize a defended but uninhabited planet (see the story). In the above image, bipedal Enforcer-style robots are being trained in the Mountain Pass arena. The behavior of each robot is controlled by an artificial neural network, i.e. a "brain". A robot enters play at a drop point near the crowded area at the right, and its brain is scored on how well the robot performs within a given amount of time. Based on these scores (or rewards), the NEAT neuroevolution algorithm then modifies the brains so that they perform better in the future. The robots in the above image have already been trained to approach enemies; several can be seen crowded around the target labeled E1 to the left, and many more are on their way. Now the player is using the reward controls (lower right) to change the scoring so that in further training, this team learns not to approach the enemy too closely. Many other options are also available on the control panel for adjusting the scoring and the environment.
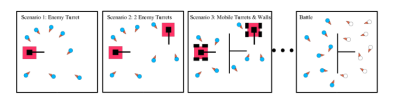
Training for complex tactical behaviors will require a player to think out and implement a shaping plan, leading the robots through a series of sandbox scenarios that guide them stepwise to the desired battlefield doctrine. In the figure above, the player first begins training with only one enemy turret as the target. A second turret is then added, making the task more difficult. Once the robots are able to handle multiple turrets,, walls are included into the environment, and the turrets are allowed to move. Finally, after the robots have been trained through all of these incrementally more difficult tasks, they are deployed in a battle against another user's trained team to see how effective the training sequence was.
Battle Mode
In battle, the trained team is put to a test. The battle takes place between two trained teams on a local area network or the Internet. The player can also place flags interactively during the battle, thus directing the team.

Screenshot in battle mode (detail).
In the above image, two trained teams are engaged in the Orchard arena, where a long wall down the center separates the two teams' starting positions but leaves room to go around either end. The Red Team (right) was trained to face the enemy and fire from a safe distance, and the Blue Team (left) was trained to chase down enemies while navigating obstacles such as the wall. Here the Blue Team has formed into single file while negotiating the turn at the end of the wall, and now assaults the Red Team, which has assumed a defensive posture. The smoke is color-coded to indicate which team is firing; the image shows that the Red Team's training has given it the advantage of a concentration of fire in this situation. During battle, the agents behave autonomously but according to their training, often resulting in surprisingly complex dynamics that is exciting to watch.
Territory Mode
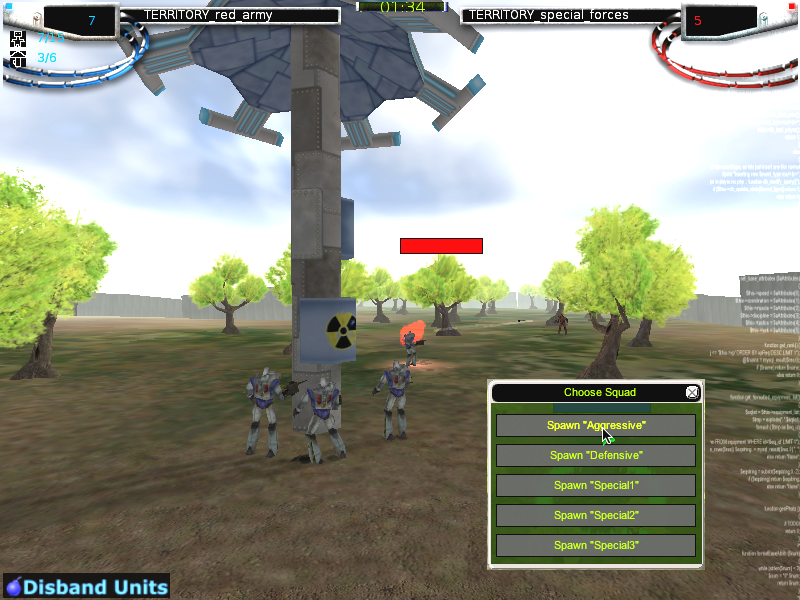
Screenshot of territory mode (detail).
NERO 2.0 introduces the Territory Mode, which allows players to participate actively when their robots compete. In this mode, the goal of the game is to capture all of the opponent's control structures. To do so, the agents must be smart enough to navigate to the control point and to establish superiority around it. The player can give high-level orders by specifying which control point the robots should target. Territory mode requires more flexible behaviors than battle mode. Therefore, the player uses a platoon, or a heterogeneous collection of separately evolved squads. The player constantly evaluates the current situation in the battle, and picks and deploys the robots with the appropriate specializations dynamically; for instance in the above figure, the player is deploying agents labeled "Aggressive". The player thus works collaboratively with the intelligent agents s/he has trained. The gameplay is interactive and fast-paced, making for an engaging game.
Real-Time Neuroevolution with rtNEAT
The artificial neural network "brains" learn by means of the NEAT or Neuro-Evolution of Augmenting Topologies algorithm. Neuroevolution is a genetic algorithm, i.e. a reinforcement learning method that operates by rewarding the agents in a population that perform the best and punishing those that perform the worst. In NERO the rewards and punishments are specified by the players, by means of the slider controls shown in the screenshot above, on the right-hand side. The genetic algorithm decides which robots' "brains" are the most and least fit on the basis of the robots' behavior and the current settings of the sliders.
Unlike most neuroevolutionary algorithms, NEAT starts with an artificial neural network of minimal connectivity and adds complexity only when it helps solve a problem. This approach helps ensure that the algorithm does not produce unnecessarily complex solutions.
Most genetic algorithms use generation-based off-line processing, and only provide a result at the end of some pre-specified amount of training. In NERO, a real-time variant of NEAT, called rtNEAT, was introduced, in which a small population evolves while you watch. The rtNEAT method solves several technical challenges. For example, in order to allow continual adaptation, rtNEAT discards the traditional notion of generations for the genetic algorithm, and instead keeps a small population that is evaluated continuously, with regular replacement of the poorest performers. This approach is powerful enough to allow a population as small as 30 to solve non-trivial learning tasks. As a result, the entire population can be replaced quickly enough for human viewers to see the population's behavior adapt while they watch.
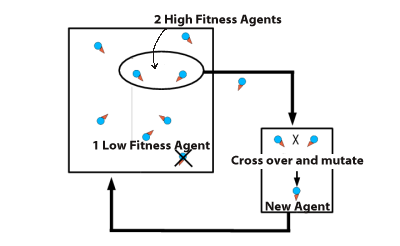
Real-time neuroevolution.
In rtNEAT, the regimented schedule of generation-based evolution is replaced by an artificial lifetime on each "brain" being evaluated. In this example the brains control individual agents in a simulation. Whenever a brain's evaluation lifetime is up, its fitness (based on the agent's performance while "wearing" that brain) is compared to the fitness of other brains in the population. If it is among the least fit brains it is immediately discarded and replaced by breeding two high-fitness brains together using NEAT. Otherwise the brain is put on the shelf, ready to be inserted into another robot for further evaluation when its turn comes up again.
Current Status and Future Work
NERO 2.0 is available for download on the Downloads page. It runs on Linux, Windows and Mac OS X platforms, and includes a tutorial on how to get started. A number of videos illustrating gameplay as well as interesting behaviors that emerge can be seen on the Videos page.
The NERO team is currently working on OpenNERO, an open source version of the NERO platform intended to serve as a tool for research in intelligent agents and teaching in Artificial Intelligence. At this point, we invite feedback from potential users. If you are interested in using such a platform in your research or teaching, please try out NERO 2.0 and send us any feedback or suggestions.
You might also want to check out a related project on evolutionary art.
Acknowledgements
Production of the NERO project is funded in part by the Digital Media Collaboratory, the IC2 Institute and the College of Natural Sciences at the University of Texas at Austin. The original NEAT research was supported in part by the National Science Foundation and the Texas Higher Education Coordinating Board.
NERO would not be possible without the contribution of current and past members of the NERO Team.
NERO 2.0 (and earlier) is built on the Torque Game Engine, licensed from GarageGames, Inc.