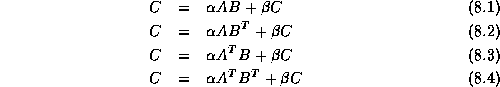We now give more details on how using our approach and library leads to elegant, efficient, and scalable implementations of matrix-matrix multiplication on distributed memory architectures.
We will consider the formation of the matrix products
and will use the techniques discussed in
Section 1.6 as well
as the implementations discussed
for the parallel implementation of matrix-vector
multiplication in Section ![]() and
rank-1 update in Section
and
rank-1 update in Section ![]() .
.