
As chips become larger and more complex, their routing algorithms must also be improved and optimized to face the challenge. Recent UT Computer Science PhD graduate Michael Jiayuan He’s research in computer chip design has made a notable step forward towards more efficient and successful chip design in the academic arena. In “SPRoute 2.0: A detailed-routability-driven deterministic parallel global router with soft capacity,” he explores solutions at the Global Routing level that make the process of detailed routing more efficient. These methods allow the computer scientist to proactively avoid shorts and create successful designs earlier along in the process, optimizing the routing phase overall.
In the industry-standard method of chip design (VSLI), there are two phases of routing: Global Routing and Detailed Routing. Global routing collapses the 3D chip into a 2D simplified grid. A way to conceptualize this phase is by thinking of it as choosing a highway to drive down during busy rush hour traffic. You simplify the roads available to a list then choose a sequence of highways that get you to your destination and are the least congested. The wires are similarly routed into available regions (highways) on the chip which gives a suggested routing configuration for the detailed routing phase to refine. If we follow the same analogy of rush hour traffic, the detailed routing phase would be like picking a lane on a busy highway. In the case of a wire’s path, only one “car” can fit in each of the available “lanes”. Global routing picks the path, detailed routing picks the specific lane. To understand the novelty of He’s method, it must first be understood that traditional global routing looks at each edge of the grid as the total set of available tracks to route wires through in that region. Typically, it will fill these areas to their full capacity which gives the detailed routing algorithms less flexibility to fix other issues that may arise when refining the design. This is where the soft capacity solution is crucial.
Soft capacity is a specific solution that attacks the problem of certain spaces in the chip being overcrowded and congested. Through running a test of the pin density (density of inputs within a section of the chip) and the RUDY (rectangular uniform wire density) which describes the average wire length per unit area in a certain bounding box of the network (the network or “net” is a set of wire connections) the computer scientist is able to predict where there will be congestion and possible shorts. The graphic below shows an example of the result a test like this yields:
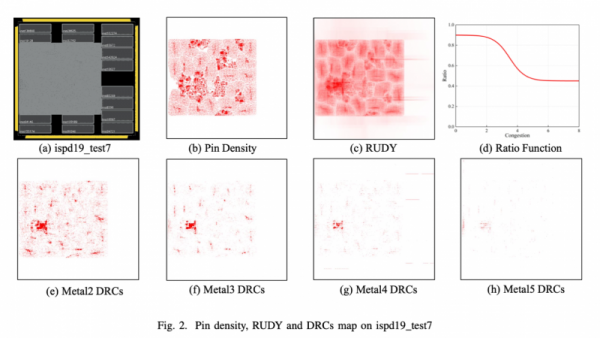
The more densely red areas are the areas that are more congested with wire connections. It is clear to see here that there is a section that is specifically darker than the rest, and therefore more likely to be overloaded and short. The soft capacity method redistributes this density by allowing less wires to be routed through that specific area. For example, if the wire capacity was 15, soft capacity would call for decreasing that number to 5 or 10 in order for the wires to be rerouted to other places on the chip and spread out the overall density.
Additionally, there is the element of improving parallelization maze routing methods to create a more efficient deterministic result. Parallelization, a technique which breaks down a complicated process into pieces that can be executed simultaneously, can actually make things less efficient if left to automatic route through pathways in this context. This is because it can create LiveLock situations like the one shown below.
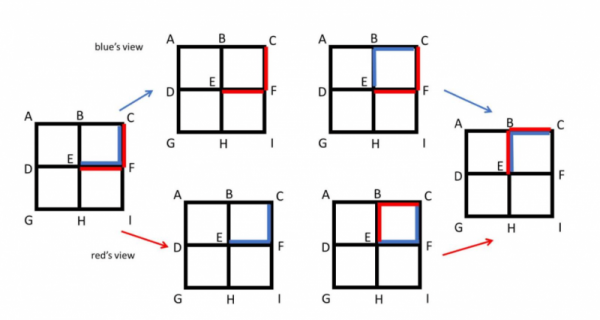
The graphic above shows how when the task of avoiding overloading of a path is parallelized, both wires move out of the way, recreating the original problem in a repeating loop. This is similar to when you and someone approaching you on the sidewalk both move in the same direction at the same time. If you keep moving out of each other’s way at the same time, you’ll always be in the way and neither of you has a free path. In these social scenarios, the solution is to wait and let the other person move before moving out of the way yourself. This logic is the same for wire routing. By executing the parallelized tasks in batches using an automated scheduler, the wires must essentially wait for the previous batch to make a decision and then react to that before making a routing decision itself. These batches are groups of wires across different areas of the chip that don’t normally interact with each other, and therefore retain the increased efficiency that comes from parallelization while also avoiding its pitfalls.
These solutions presented in He’s research not only logically make sense as ways to increase efficiency, but the SPRoute 2.0 methodology also shows impressive experimental results. SPRoute 2.0 produces 43% fewer shorts, 14% fewer Design Rule Checks (DRCs), and a 7.4x speedup over a state of the art global router on the ICCAD2019 contest benchmarks for which this research was prepared.