Unit 3.1.2 Outline Week 3
¶-
3.1 Opening Remarks
3.1.1 Launch
3.1.2 Outline Week 3
3.1.3 What you will learn
-
3.2 Leveraging the Caches
3.2.1 Adding cache memory into the mix
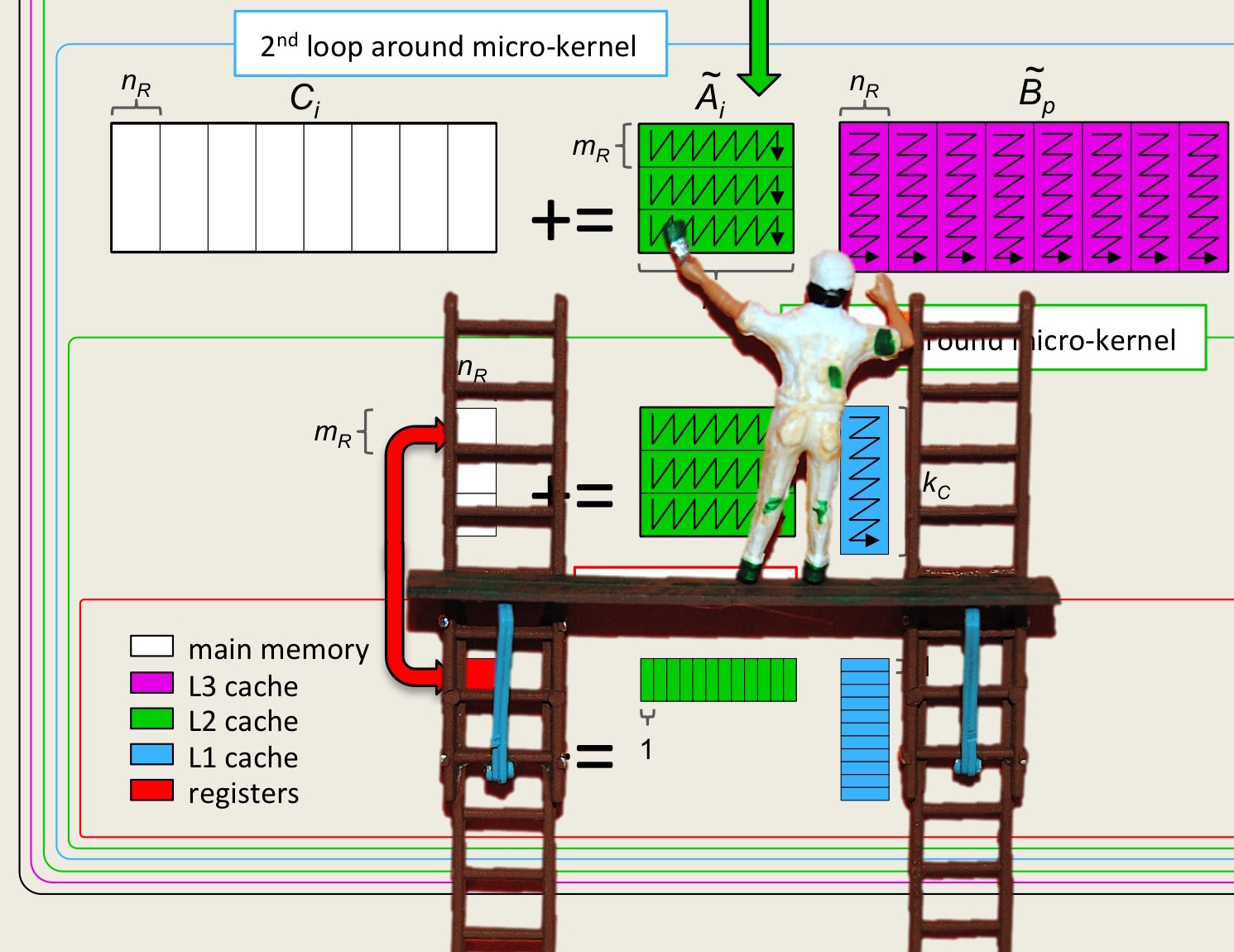
3.2.2 Streaming submatrices of \(C \) and \(B \)
3.2.3 Which cache to target?
3.2.4 Blocking for the L1 and L2 caches
3.2.5 Blocking for the L1, L2, and L3 caches
3.2.6 Translating into code
-
3.3 Packing
3.3.1 Stride matters
3.3.2 Packing blocks of \(A \) and panels of \(B \)
3.3.3 Implementation: packing row panel \(B_{p,j} \)
3.3.4 Implementation: packing block \(A_{i,p} \)
3.3.5 Implementation: five loops around the micro-kernel, with packing
3.3.6 Micro-kernel with packed data
-
3.4 Further Tricks of the Trade
3.4.1 Alignment
3.4.2 Avoiding repeated memory allocations
3.4.3 Play with the block sizes
3.4.4 Broadcasting elements of \(A \) and loading elements of \(B \)
3.4.5 Loop unrolling
3.4.6 Prefetching
3.4.7 Using in-lined assembly code
-
3.5 Enrichments
3.5.1 Goto's algorithm and BLIS
3.5.2 How to choose the blocking parameters
3.5.3 Alternatives to Goto's algorithm
3.5.4 Practical implementation of Strassen's algorithm
-
3.6 Wrap Up
3.6.1 Additional exercises
3.6.2 Summary