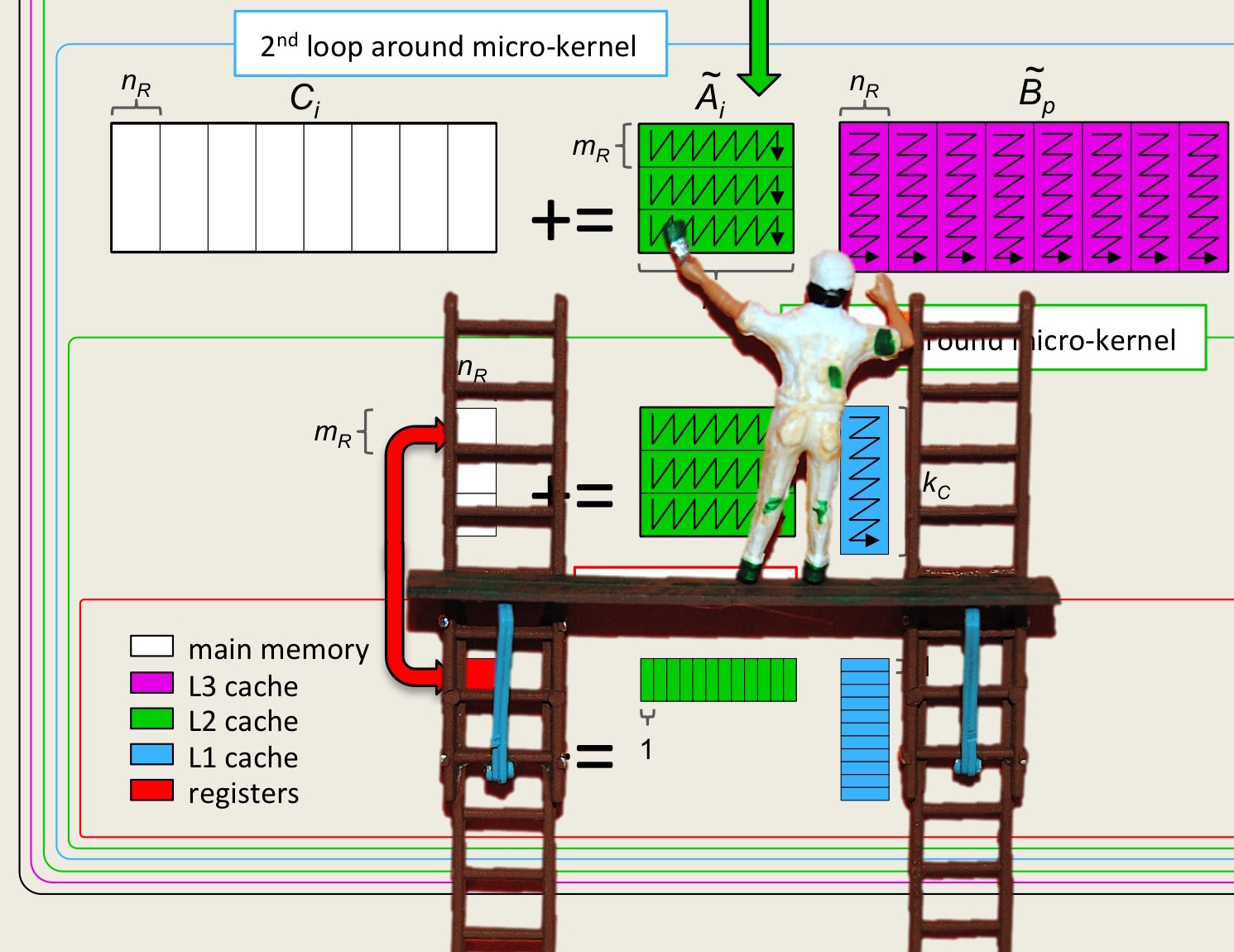
Unit 4.3.6 Parallelizing the fifth loop around the micro-kernel
¶Finally, let us consider how to parallelize the fifth loop around the micro-kernel:

and observe that the updates of the submatrices of \(C \) can happen in parallel.
Homework 4.3.6.1.
In directory Assignments/Week4/C,
Copy Gemm_MT_Loop2_MRxNRKernel.c. into Gemm_MT_Loop5_MRxNRKernel.c.
Modify it so that only the fifth loop around the micro-kernel is parallelized.
Execute it with
export OMP_NUM_THREADS=4 make MT_Loop5_8x6Kernel
Be sure to check if you got the right answer!
View the resulting performance with data/Plot_MT_performance_8x6.mlx, uncommenting the appropriate sections.

The zigzagging in the performance graph is now so severe that you can't even see it yet by the time you test matrices with \(m=n=k=2000\text{.}\) This has to do with the fact that \(n / NC \) is now very small. If \(n = 2000\text{,}\) \(NC = 2016 \) (which is what it is set to in the makefile), and we use \(4 \) threads, then \(n / NC \approx 1 \) and hence only one thread is assigned any computation.
So, you need to come up with a way so that most computation is performed using full blocks of \(C \) (with \(NC\) columns each) and the remainder is evenly distributed amongst the threads.
Homework 4.3.6.2.
Copy Gemm_MT_Loop5_MRxNRKernel.c. into Gemm_MT_Loop5_MRxNRKernel_simple.c to back up the simple implementation. Now go back to Gemm_MT_Loop5_MRxNRKernel.c and modify it so as to smooth the performance, inspired by the last video.
Execute it with
export OMP_NUM_THREADS=4 make MT_Loop5_8x6Kernel
Be sure to check if you got the right answer!
View the resulting performance with data/Plot_MT_performance_8x6.mlx.

What we notice is that parallelizing the fifth loop gives good performance when using four threads. However, once one uses a lot of threads, the part of the row panel of \(B\) assigned to each thread becomes small, which means that the any overhead associated with packing and/or bringing a block of \(A \) into the L2 cache may not be amortized over enough computation.