CS 314 - Specification 10 - Huffman Coding and Compression
Programming Assignment 10: (Pair Assignment) You may work with one other person on this assignment using the pair programming technique. If you work with a partner, you must work with someone in the same section as you. You can complete the assignment on your own if you wish. If you use slip days each partner must have the required number of slip days or the assignment is a 0.
You and your partner may not acquire from any source (e.g. another student, an internet site, a large language model or generative AI or coding assistant such as chatGPTor Copilot) a partial or complete solution to a problem or project that has been assigned. You and your partner may not show other students your solution to an assignment. You may not have another person (current student other than your partner, former student, tutor, friend, anyone) “walk you through” how to solve an assignment. You may get help from the instructional staff. You may discuss general ideas and approaches with other students. Review the class policy on collaboration from the syllabus. If you took CS314 in a previous semester and worked with a partner on this assignment then, you must now start from scratch on the assignment. Likewise, if you took CS314 in a previous semester (regardless of if you worked by yourself or with a partner) and work with a partner this semester, you must start from scratch.
The purposes of this assignment are:
Restriction: You may not use the Java PriorityQueue class in any way on this assignment. You are expected to implement your own PriorityQueue314 without looking at any outside resources. You may, but are not required to, use the Java LinkedList or Java ArrayList as your internal storage container for your PriorityQueue.
Many, many thanks to Owen Astrachan of Duke University for allowing me to use and modify his version of this assignment.
Preparation
There is a lot to do. This is a complicated problem and program. Start early. Read the documentation for the provided classes and the how-to. Ask question on Ed and in help hours. Code a bit and then TEST YOUR CODE before moving on.
Because the compression scheme involves reading and writing in bits as opposed to a chars or Strings, the program can be hard to debug. In order to facilitate the design/code/test cycle, you should take care to develop the program in an incremental fashion. If you try to write the whole program at once, it will be difficult to get a completely working program. Past students have suffered much pain because they made an error in the code they wrote early, their PriorityQueue for example, didn't test it, and spent HOURS trying to find the bug. The howto development section has more information on incremental development.
I have also provided a few files the data portion only of a file as the characters '0' and '1' along with spaces as separator characters. These can be used to check part of your work.
Finally, some students have suggested they understood the file format much better after doing the decoder first and the encoder second. Your mileage may vary, but doing the decoder may make doing the encoder easier. (I think whatever you do second, decoder or encoder, will be easier than what you do first.)
Summary:
Implement a program that performs Huffman coding and compression on files of any type by reading in the file a byte at a time and interpreting the bytes as ints. You are given a number of classes to start with. Your solution will use many different classes. This is a difficult assignment. The hardest (and most rewarding) of the semester. I strongly urge you to work with a partner you know and trust AND to start early.
For a review of Huffman coding see the class slides. Note, your actual results shall be different than the first example in the middle of slides because the period character will be before any of the other letters in the initial priority queue AND because the example does not show the PSEUDO - EOF character with a frequency of 1.
Your algorithm output shall match the example at the end of the slides.
Background
There are many techniques used to compress digital data. This assignment implements the Huffman coding algorithm.
The MP3 codec uses Huffman encoding as one of the steps of the algorithm.
Huffman coding was invented by David Huffman while he was a graduate student at MIT in 1950 when given the option of a term paper or a final exam. For details see this 1991 Scientific American Article. In an autobiography Huffman had this to say about the epiphany that led to his invention of the coding method that bears his name:
"-- but a week before the end of the term I seemed to have nothing to show for weeks of effort. I knew I'd better get busy fast, do the standard final, and forget the research problem. I remember, after breakfast that morning, throwing my research notes in the wastebasket. And at that very moment, I had a sense of sudden release, so that I could see a simple pattern in what I had been doing, that I hadn't been able to see at all until then. The result is the thing for which I'm probably best known: the Huffman Coding Procedure. I've had many breakthroughs since then, but never again all at once, like that. It was very exciting."
Huffman's original paper is available, though it's a tough read. The Wikipedia reference is extensive. Both jpeg and mp3 encodings use Huffman Coding as part of their compression algorithms. In this assignment you'll implement a program to encode and decode files using a Huffman coding algorithm, hopefully resulting in a smaller, compressed file.
Build a program that performs two related tasks: compressing (huff) files and uncompressing (unhuff) files that are compressed by the first part of the program. This is done via a single program with the choice of compressing a file or uncompressing a file specified by choosing a menu-option in the GUI front-end to the code you write. Abstractly you're writing a program to read an input file and create a corresponding output file --- either from uncompressed to compressed or vice versa.
The Huff class is a simple main that launches a GUI
(or a text based interface) with a
connected IHuffProcessor implementation. The implementation
corresponds to an object oriented model named the model-view architecture or
pattern. In this pattern the view/(GUI or text interface) makes calls on the model/IHuffProcessor
methods which in turn may display information in the view/(GUI or text
interface). The code you
write will also create files of compressed or uncompressed data when the
GUI or text interface front end calls methods you will write. You'll implement methods and store
state (instance variables) in your IHuffProcessor implementation so that it can either
compress/huff or uncompress/unhuff. You should implement additional classes
to break the problem up into smaller, more manageable pieces and prevent
repeated code. You should have a
class that models a Huffman code tree, and a priority queue. You may find it
useful to have separate classes to manage the
details of compression (Compressor) and decompression (Decompress)
but this is not required.
With these additional classes the SimpleHuffProcessor remains
relatively small.
The howto for this assignment contains a lot of details and explanations. Please realize some the code and pseudo-code in the howto will have to be adapted to your program. Not meant to be a straight copy and paste.
The resulting program will be a complete and useful compression program although not, perhaps, as powerful as other programs such as winrar or zip which use different algorithms resulting in a higher degree of compression than Huffman coding in most instances.
Important Constraints: These will make more sense after you get going on the assignment. These constraints are necessary to test and grade your program.
FRONT [[X, 1], [A, 6], [E, 6], [S, 10]] BACK
now enqueue [Y, 6]. This value
must come after the [E, 6], but before the [S,10]
resulting priority queue after enqueuing [Y, 6]
FRONT
[[X, 1], [A, 6], [E, 6], [Y, 6], [S, 10]] BACKreset method from the Java InputStream class. The test harness
uses an InputStream that does not support that method and simply throws an
exception. You will fail many, many tests if you rely on the Java
InputStream reset method.The
Howto compression section has complete information on how to create a
compressed file. Create a Huffman tree to derive
per-chunk encodings, then write bits based on these encodings. The
Huff main program has a GUI front-end whose menu offers four choices:
count chunk values, compress, uncompress, and quit as a fourth choice.
The count option is a diagnostics and "what if" tool. It counts chunks, generates Huffman codes, and determines the number of bits in the resulting file if it were to be written using the new Huffman Codes determined by this method along with all required header data. This option does not actually write any data out to a new file. Note, to determine the number of bits saved, the number of bits written includes ALL bits that will be written including the magic number, the header format number, the header to reproduce the tree, AND the actual data.
The compress option performs the same operations as the count characters option, but also writes the data out to a file. Note, the compress option in the HuffViewer will first call the preprocess compress method BEFORE calling the compress method. The user is NOT required to call count before compress. The interface will call preprocessCompress and the compress if the user selects the compress option.
Your SimpleHuffProcessor has a reference back to the
HuffViewer. It shall make calls to the HuffViewer
showError, showMessage, and update
methods to display the status, codes, and other information. Do not use System.out.println, use the methods
from the HuffViewer.
In the code you turn in, only make reference to the data type IHuffViewer. Do not refer to any potential implementations of IHuffViewer such as GUIHuffViewer. There is no guarantee any particular implementation of IHuffViewer will be used when we grade.
The preprocessCompress method must return the number of bits in the original file
- the number of bits written to the compressed file (including the Huffman magic
number, the header constant, the header, the data, and the pseudo-eof, but NOT
any padding added by the file system to get the file size up to a multiple of
8.)
The compress method returns the number of bits actually written.
It also writes out the compressed file using the codes generated from the
previous call to preprocessCompress. A precondition to compress is that
preprocessCompress has already been called.
The uncompress option is used to decompress a file. The uncompress method returns the number of bits written to the output file.
It also uncompresses the compressed file.
To uncompress a file your program previously compressed you'll need to read header information from the compressed file your program (or other versions of the Huffman compressor) creates. The header information is data used to recreate the Huffman tree that was originally used to compress the data. Your code will then read one-bit-at-a-time to uncompress the data and recreate the original file. There's information in the howto uncompress section on doing this.
Read the header
information to recreate the tree, then do a tree-walk one bit at a time to find
the characters stored in the leaves of the Huffman tree. Each time you find a
leaf, write the value to the output (and if debugging, to the HuffView
interface.). This process recreates the original, uncompressed file.
The uncompress option is used to decompress a file.
Run the program
HuffMark which will read every file in a directory and compress it to
another file in the same directory with a ".hf" suffix. The
HuffMark program does not provide a viewer for your
SimpleHuffProcessor so you have to comment out any calls to
showString or viewer.showMessage. You can leave in the calls
to showError assuming you won't suffer any errors. The method calls
may be in other classes if you created separate Compressor and
Decompressor classes.
You may want to modify this benchmarking program to print more data than it currently does, and to run it on the calgary directory which represents the Calgary Corpus, a standard compression suite of files for empirical analysis. See this reference for comparisons of the Calgary Corpus, and the waterloo directory which is a collection of .tiff images used in some compression benchmarking, and on the BooksAndHTML directory which contains a number of text files and html documents. All of those collections are in zip files which you must download and unzip. You can, of course, run on other data/collections.
The benchmarking program skips files with .hf suffixes, but you may want to eventually remove this restriction . (In other words, what happens if you take a compressed file and try and compress it again?) In your assignment write-up discuss your benchmark results and provide some insight as to their meaning. Your analysis is worth 15% of your grade on this assignment, so you should try to come to some conclusions in addition to simply listing your results.
Some Results From my version of the program.
This small sample file (that contains "Eerie eyes seen near lake.") is 26 bytes or 208 bits.
When I "compress" is with the Standard Count Format
Header
(see how-to document for explanation) the resulting size is 8346
bits. (The resulting file is 8352 bits, not 8346 bits. Why? 8346 is 1043.25
bytes. Or 1043 bytes and 2 bits. The file must be written as bytes so there are
6 bits of padding. This is the whole purpose of the pseudo-eof character. To
know when the real data has ended and to ignore whatever padding may follow.)
When I "compress" it with the Standard Tree Format
Header
the resulting size is 328 bits.
The 2008 CIA Factbook is 9,637,228 bytes or 77,097,824 bits
When I compress it with the Standard Count Format
Header the compressed file is 48,230,392 bits.
When I compress it with the Standard Tree Format Header the compressed file is 48,223,298 bits.
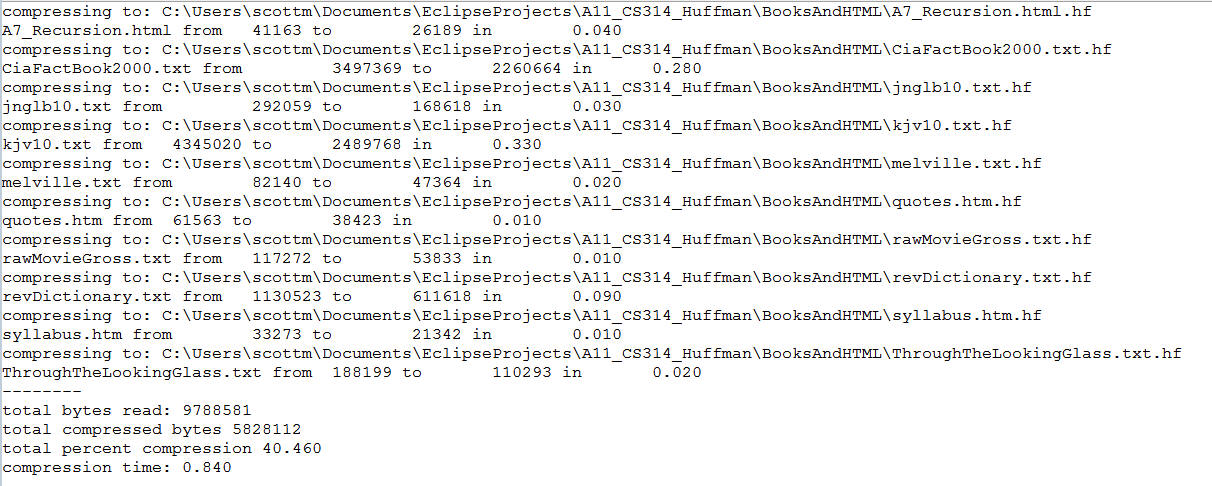
When I run HuffMark on the BooksAndHTML directory I get these results (Note, your times DO NOT have match these.):
My solution to the problem, which supports the
standard count headers and
the tree headers, consists of 4 classes in addition to the SimpleHuffProcessor
with on the order of 650 lines including code, blank lines, lines with single braces, and
comments. (lots of comments)
| File | Responsibility | |
| Starter Code |
HuffmanSource.zip
A zip file with the given classes to use in the assignment. You will make
significant additions to SimpleHuffProcessor. Do not make
any changes to the other given classes or interfaces. Your solution
shall follow good object oriented design. Create new classes as
necessary. Do not stick all your code into SimpleHuffProcessor.
Unless you like losing hygiene points. |
Provided by me and you |
| Guide | The Huffman HOWTO page is a guide to help you complete the assignment. It gives an overview of the various parts of the assignment. And a second howto written by a past TA, Claire. (Here is the original, hand written version which I find charming.) | Provided by me |
| Sample Output |
There is a GUI implementation of IHuffViewer and a text
based implementation of the same interface. By default the Huff.java
program creates a GUI interface. This can be easliy changed by
commenting out one line and commenting in the next line in the main
method of Huff.java. If you use the text based interface to work on the assignment here is some sample output from the interface. |
Provided by me |
| Documentation | Documentation for the provided, non standard Java classes. You will have to refer to the documentation a great deal. | Provided by me |
| Small Test File |
The small text file contains "Eerie eyes seen near lake." smallTxt.txt, SmallTxtCountHeader.txt.hf, and SmallTxtTreeHeader.txt.hf. Small sample file to use when incrementally developing your program. smallTextsFreqsAndCodes.txt contains the expected frequencies and Huffman codes for this file. Here is the complete small text file with 1s and 0s shown as chars, not stored as bits: You can use this ExplicitBitOutputWriter.java class to convert any file to a file with ASCII 0's and 1's. This is useful when looking at small files. You can compare files in Eclipse to find differences. See this page for instructions. Of course there are other programs that allow you to view the data in a file as raw 1's and 0's such as xxd on variations of Unix. You may also find it useful to use a program that has the ability to view files as raw hexadecimal values. I use TextPad but of course there are many options.
|
Provided by me |
| Large Test File |
The 2008 CIA Factbook. The
ciaFactbook2008FreqsAndCodes.txt contains the expected frequencies
and Huffman codes for this file, plus the standard tree for that file.
ciaFactbook2008.txt.hf is the compressed file using the standard
count format.
ciaFactbook2008_stf.txt.hf is the compressed file using the standard
tree format. Take great care to download the text and be sure the file is not altered in the process. Do not open in a web browser and copy and paste. This version of the CIA Factbook uses ASCII / Unicode value 10 for newlines. As opposed to the Windows standard of ASCII / Unicode values 10 and 13 for new lines. None of the byte values in the text equal 13. If you are getting any count other than 0 for value 13, you have a corrupted version of the CIA Factbook. If you copy and paste or open up and then save the file in Windows then, you system or software may add in an extra character for new lines. Be sure the size of the CIA Factbook file on your system is 9,637,228 bytes exactly.
Explicit Bit Version of the header (no actual compressed data) Standard Count Format (8256 bits)and Standard Tree Format (1130 bits) for the CIA Factbook. These can be useful for debugging. |
Provided by me |
| Large Test Files |
Here are a couple of files to test your
de-compressor. I am not giving you the original file. |
Provided by me |
| Test Framework and Files |
Another way to test your file:
A10_Huffman_Test_Student_Version. This is the similar in nature to
the test harness we will
use when testing your submission. There are difference and of course we will use different files. Instead of using the
A GUI or text based interface we use this implementation of IHuffViewer, a
DoNothingHuffViewer when running the test harness. I
recommend you create a separate package in your Eclipse project for
these test files OR a whole different project from your working code. To use the harness you need to download the bevotest.jar file created by John Thywissen (former CS314 TA who wrote the testing framework we use to grade programs). bevotest.jar is a collection of code you need for the A10_Huffman_Test_Student_Version to work. (The jar contains various .class files.) See this page for info on how to include a jar in your Eclipse project. Finally you need the test files in this zip file. Download and unzip the file to your Eclipse project folder. |
Provided by me |
| Files for Analysis | calgary.zip, waterloo.zip, and BooksAndHTML.zip zip files with lots of large files to test your finished program. Unzip the files and use the HuffMark program / class to test your solution. | Links provided by me |
| Write Up | README.txt Write up will be an analysis of your experiments. What kinds of file lead to lots of compressions. What kind of files had little or no compression? What happens when you try and compress a huffman code file? | Provided by you |
| Yet More Test Files | A zip with 6 more test files, the compressed files in SCF and STF, and text results of counts and codes from a former student and TA, Skyler V. | |
| All Files | All files except documentation in one zip. | Provided by me |
| Submission | In the code you turn in, only make reference to the data type IHuffViewer. Do not refer to any potential implementations of IHuffViewer such as GUIHuffViewer. There is no guarantee any particular implementation of IHuffViewer will be used when we grade. | Provided by you |
Submission: Add the standard header to the SimpleHuffProcessor.java and copy it into the classes your create for the assignment. Replace <NAME1> with your name and <NAME2> with your partner's name if working with a partner. Note, you are stating, on your honor, that you did the assignment on your own or with your partner.
Turn in all the required files to the proper assignment on GradeScope.
Checklist: Did you remember to:
{kind=link}
{kind=link}
{kind=link}