Subsection 4.3.2 Case 1: \(A \) has linearly independent columns
¶Let us start by discussing how to use the SVD to find \(\widehat x \) that satisfies
for the case where \(A \in \Cmxn \) has linearly independent columns (in other words, \(\rank( A ) = n \)).
Let \(A = U_L \Sigma_{TL} V^H \) be its reduced SVD decomposition. (Notice that \(V_L = V\) since \(A \) has linearly independent columns and hence \(V_L \) is \(n \times n \) and equals \(V \text{.}\))
Here is a way to find the solution based on what we encountered before: Since \(A \) has linearly independent columns, the solution is given by \(\widehat x = ( A^H A )^{-1} A^H b\) (the solution to the normal equations). Now,
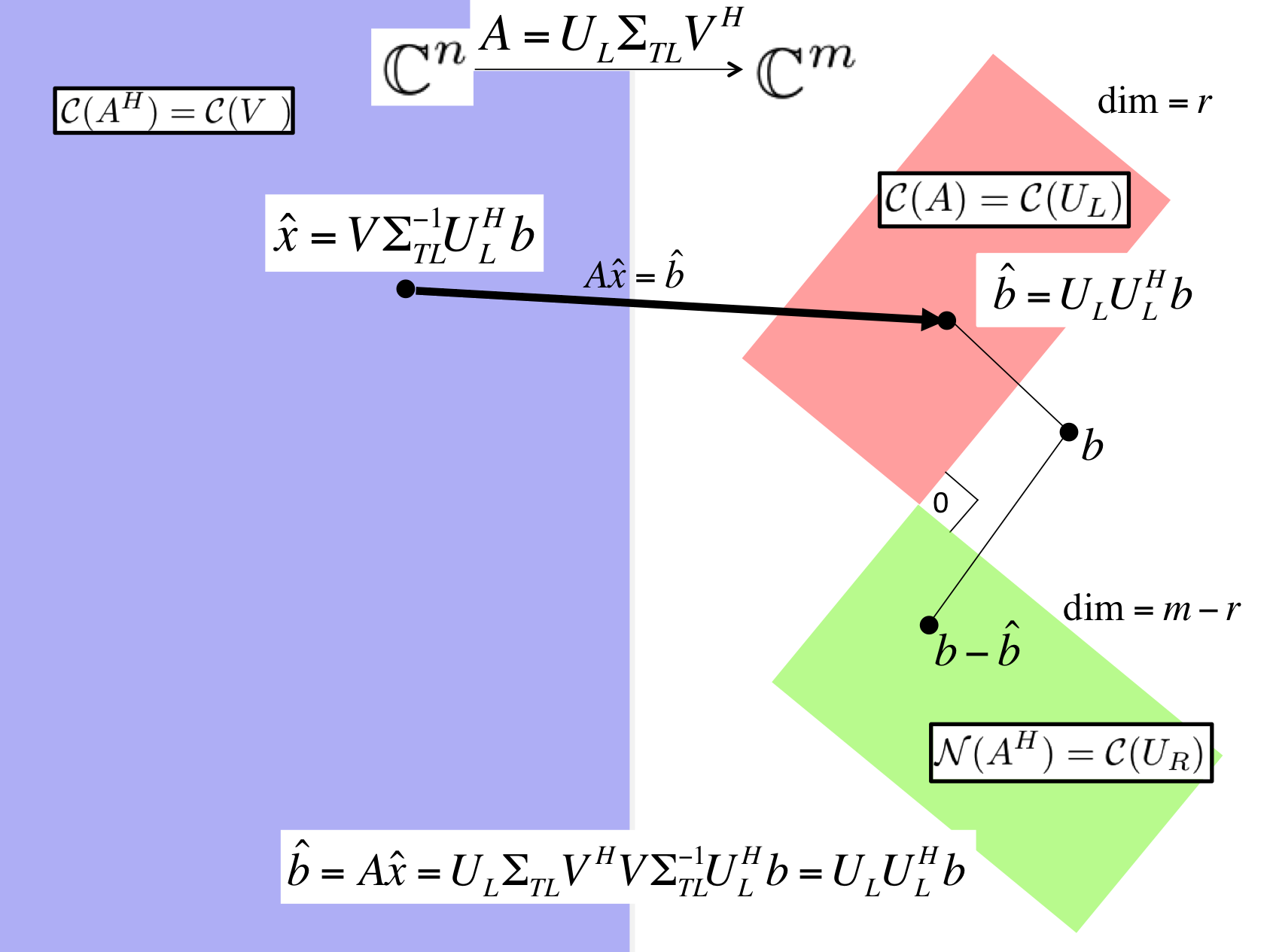
images/Chapter04/FundamentalSpacesSVDLLSLinIndep.pptxAlternatively, we can come to the same conclusion without depending on the Method of Normal Equations, in preparation for the more general case discussed in the next subsection. The derivation is captured in Figure 4.3.2.1.
The \(x \) that solves \(\Sigma_{TL} V^H x = U_L^H b \) minimizes the expression. That \(x \) is given by
since \(\Sigma_{TL} \) is a diagonal matrix with only nonzeroes on its diagonal and \(V \) is unitary.
Here is yet another way of looking at this: we wish to compute \(\widehat x \) that satisfies
for the case where \(A \in \Cmxn \) has linearly independent columns. We know that \(A = U_L \Sigma_{TL} V^H \text{,}\) its Reduced SVD. To find the \(x \) that minimizes, we first project \(b \) onto the column space of \(A \text{.}\) Since the column space of \(A \) is identical to the column space of \(U_L \text{,}\) we can project onto the column space of \(U_L \) instead:
(Notice that this is not because \(U_L \) is unitary, since it isn't. It is because the matrix \(U_L U_L^H\) projects onto the columns space of \(U_L \) since \(U_L\) is orthonormal.) Now, we wish to find \(\widehat x \) that exactly solves \(A \widehat x = \widehat b \text{.}\) Substituting in the Reduced SVD, this means that
Multiplying both sides by \(U_L^H \) yields
and hence
We believe this last explanation probably leverages the Reduced SVD in a way that provides the most insight, and it nicely motivates how to find solutions to the LLS problem when \(\rank( A ) \lt r \text{.}\)
The steps for solving the linear least squares problem via the SVD, when \(A \in \Cmxn \) has linearly independent columns, and the costs of those steps are given by
-
Compute the Reduced SVD \(A = U_L \Sigma_{TL} V^H \text{.}\)
We will not discuss practical algorithms for computing the SVD until much later. We will see that the cost is \(O( m n^2 ) \) with a large constant.
-
Compute \(\widehat x = V \Sigma_{TL}^{-1} U_L^H b \text{.}\)
The cost of this is approximately,
Form \(y_T = U_L^H b \text{:}\) \(2 m n \) flops.
Scale the individual entries in \(y_T \) by dividing by the corresponding singular values: \(n \) divides, overwriting \(y_T = \Sigma_{TL}^{-1} y_T \text{.}\) The cost of this is negligible.
Compute \(\widehat x = V y_T \text{:}\) \(2 n^2 \) flops.
The devil is in the details of how the SVD is computed and whether the matrices \(U_L \) and/or \(V \) are explicitly formed.