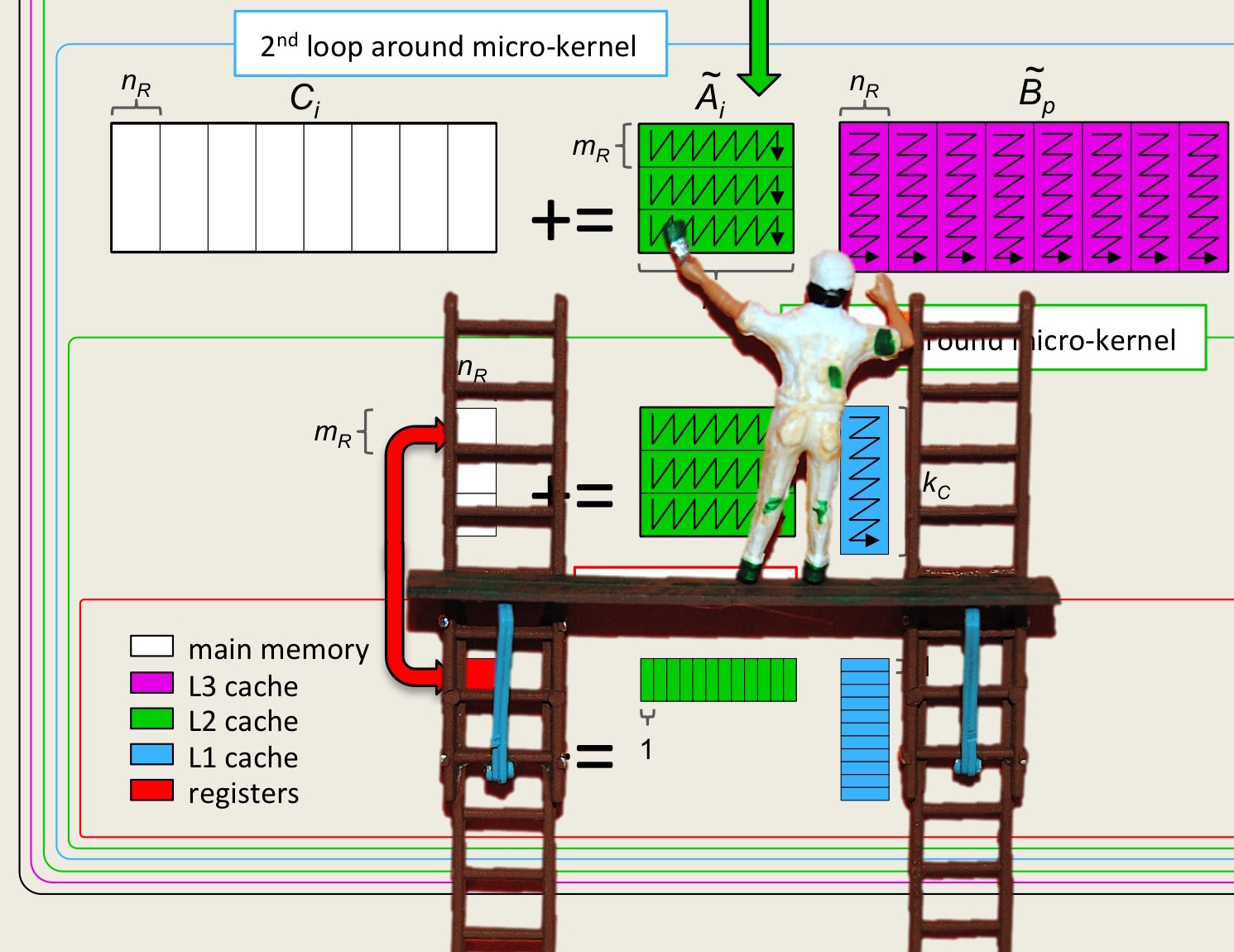
This unit is one of the most important ones in the course. Take your time to understand it. The syntax of the intrinsic library is less important than the concepts: as new architectures become popular, new vector instructions will be introduced.
In this section, we are going to AVX2 vector instruction set to illustrate the ideas. Vector intrinsic functions support the use of these instructions from within the C programming language. You discover how the intrinsic operations are used by incorporating them into an implemention of the micro-kernel for the case where \(m_R
\times n_R = 4 \times 4 \text{.}\) Thus, for the remainder of this unit, \(C \) is \(m_R \times n_R = 4 \times 4
\text{,}\) \(A \) is \(m_R \times k = 4 \times k \text{,}\) and \(B \) is \(k \times n_R = k \times 4 \text{.}\)
The architectures we target have 256 bit vector registers, which mean they can store four double precision floating point numbers. Vector operations with vector registers hence operate with vectors of size four.
void MyGemm( int m, int n, int k, double *A, int ldA,
double *B, int ldB, double *C, int ldC )
{
if ( m % MR != 0 || n % NR != 0 ){
printf( "m and n must be multiples of MR and NR, respectively \n" );
exit( 0 );
}
for ( int j=0; j<n; j+=NR ) /* n is assumed to be a multiple of NR */
for ( int i=0; i<m; i+=MR ) /* m is assumed to be a multiple of MR */
Gemm_MRxNRKernel( k, &alpha( i,0 ), ldA, &beta( 0,j ), ldB, &gamma( i,j ), ldC );
}
Figure2.4.2. General routine for calling a \(m_R \times n_R \) kernel in Assignments/Week2/C/Gemm_JI_MRxNRKernel.c. The constants MR and NR are specified at compile time by passing -D'MR=??' and -D'NR=??' to the compiler, where the ??s equal the desired choices of \(m_R \) and \(n_R \) (see also the Makefile in Assignments/Week2/C).
Let's drop the subscripts, and focus on computing \(C +:= A B \) when \(C \) is \(4
\times 4 \text{,}\) with the micro-kernel. This translates to the computation
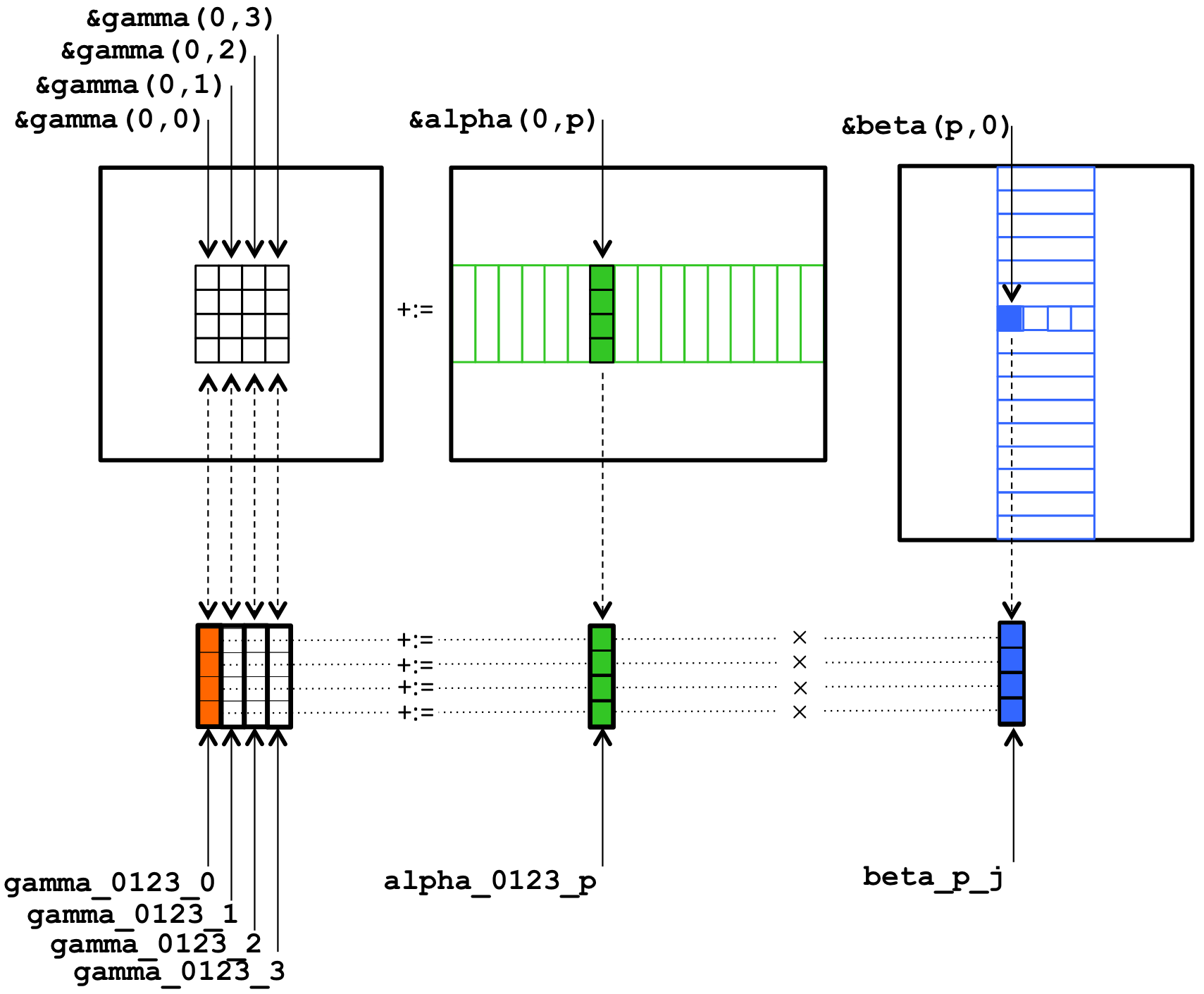
This, once again, shows how matrix-matrix multiplication can be cast in terms of a sequence of rank-1 updates, and that a rank-1 update can be implemented in terms of axpy operations with columns of \(C \text{.}\) This micro-kernel translates into the code that employs vector instructions, given in Figure 2.4.3. We hope that the instrinsic function calls are relatively self-explanatory. However, you may want to consult Intel's Intrinsics Reference Guide. When doing so, you may want to search on the name of the routine, without checking the AVX2 box on the left.
#include <immintrin.h>
void Gemm_MRxNRKernel( int k, double *A, int ldA, double *B, int ldB,
double *C, int ldC )
{
/* Declare vector registers to hold 4x4 C and load them */
__m256d gamma_0123_0 = _mm256_loadu_pd( &gamma( 0,0 ) );
__m256d gamma_0123_1 = _mm256_loadu_pd( &gamma( 0,1 ) );
__m256d gamma_0123_2 = _mm256_loadu_pd( &gamma( 0,2 ) );
__m256d gamma_0123_3 = _mm256_loadu_pd( &gamma( 0,3 ) );
for ( int p=0; p<k; p++ ){
/* Declare vector register for load/broadcasting beta( p,j ) */
__m256d beta_p_j;
/* Declare a vector register to hold the current column of A and load
it with the four elements of that column. */
__m256d alpha_0123_p = _mm256_loadu_pd( &alpha( 0,p ) );
/* Load/broadcast beta( p,0 ). */
beta_p_j = _mm256_broadcast_sd( &beta( p, 0) );
/* update the first column of C with the current column of A times
beta ( p,0 ) */
gamma_0123_0 = _mm256_fmadd_pd( alpha_0123_p, beta_p_j, gamma_0123_0 );
/* REPEAT for second, third, and fourth columns of C. Notice that the
current column of A needs not be reloaded. */
}
/* Store the updated results */
_mm256_storeu_pd( &gamma(0,0), gamma_0123_0 );
_mm256_storeu_pd( &gamma(0,1), gamma_0123_1 );
_mm256_storeu_pd( &gamma(0,2), gamma_0123_2 );
_mm256_storeu_pd( &gamma(0,3), gamma_0123_3 );
}
Figure2.4.3. Partially instantiated \(m_R \times n_R \) kernel for the case where \(m_R = n_R = 4 \) (see Assignments/Week2/C/Gemm_4x4Kernel.c).