Invariant local features, instance recognition, visual vocabularies and bag-of-words

-
*Object Recognition from Local Scale-Invariant Features, Lowe, ICCV 1999. [pdf] [code] [other implementations of SIFT] [IJCV]
-
*Selected pages from: Local Invariant Feature Detectors: A Survey, Tuytelaars and Mikolajczyk. Foundations and Trends in Computer Graphics and Vision, 2008. [pdf] [Oxford code] [Read pp. 178-188, 216-220, 254-255]
-
*Video Google: A Text Retrieval Approach to Object Matching in Videos, Sivic and Zisserman, ICCV 2003. [pdf] [demo]
-
For more background on feature extraction: Szeliski book: Sec 3.2 Linear filtering, 4.1 Points and patches, 4.2 Edges
-
Scalable Recognition with a Vocabulary Tree, D. Nister and H. Stewenius, CVPR 2006. [pdf]
-
SURF: Speeded Up Robust Features, Bay, Ess, Tuytelaars, and Van Gool, CVIU 2008. [pdf] [code]
-
Robust Wide Baseline Stereo from Maximally Stable Extremal Regions, J. Matas, O. Chum, U. Martin, and T. Pajdla, BMVC 2002. [pdf]
-
A Performance Evaluation of Local Descriptors. K. Mikolajczyk and C. Schmid. CVPR 2003 [pdf]
- Oxford group interest point software
- Andrea Vedaldi's VLFeat code, including SIFT, MSER, hierarchical k-means.
- INRIA LEAR team's software, including interest points, shape features
- FLANN - Fast Library for Approximate Nearest Neighbors. Marius Muja et al.
- Google Goggles
- Kooaba
[filters]
[local features]
[matching and spatial verification]
Scalable retrieval algorithms, mining for visual themes, particularly for object instances

-
*Total Recall: Automatic Query Expansion with a Generative Feature Model for Object Retrieval. O. Chum et al. CVPR 2007. [pdf] [Oxford buildings dataset]
-
*Discovering Favorite Views of Popular Places with Iconoid Shift. T. Weyand and B. Leibe. ICCV 2011. [pdf] [Paris 500K dataset]
-
*Supervised Hashing with Kernels. W. Liu, J. Wang, R. Ji, Y. Jiang, S.-F. Chang. CVPR 2012 [pdf]
-
Kernelized Locality Sensitive Hashing for Scalable Image Search, by B. Kulis and K. Grauman, ICCV 2009 [pdf] [code] [80M Tiny Images data]
- Image Webs: Computing and Exploiting Connectivity in Image Collections. K. Heath, N. Gelfand, M. Ovsjanikov, M. Aanjaneya, and L. Guibas. CVPR 2010. [pdf]
-
World-scale Mining of Objects and Events from Community Photo Collections. T. Quack, B. Leibe, and L. Van Gool. CIVR 2008. [pdf]
-
Total Recall II: Query Expansion Revisited. O. Chum, A. Mikulik, M. Perdoch, and J. Matas. CVPR 2011. [pdf]
-
Geometric Min-Hashing: Finding a (Thick) Needle in a Haystack, O. Chum, M. Perdoch, and J. Matas. CVPR 2009. [pdf]
-
Three Things Everyone Should Know to Improve Object Retrieval. R. Arandjelovic and A. Zisserman. CVPR 2012. [pdf]
-
Video Mining with Frequent Itemset Configurations. T. Quack, V. Ferrari, and L. Van Gool. CIVR 2006. [pdf]
-
Bundling Features for Large Scale Partial-Duplicate Web Image Search. Z. Wu, Q. Ke, M. Isard, and J. Sun. CVPR 2009. [pdf]
-
Improving Image-based Localization by Active Correspondence Search. T. Sattler, B. Leibe, L. Kobbelt. ECCV 2012. [pdf]
-
Learning Binary Projections for Large-Scale Image Search. K. Grauman and R. Fergus. Chapter to appear in Registration, Recognition, and Video Analysis, R. Cipolla, S. Battiato, and G. Farinella, Editors. [pdf]
-
Learning Query-dependent Prefilters for Scalable Image Retrieval. L. Torresani, M. Szummer, and A. Fitzgibbon. CVPR 2009. [pdf]
-
Detecting Objects in Large Image Collections and Videos by Efficient Subimage Retrieval, C. Lampert, ICCV 2009. [pdf] [code]
-
Efficiently Searching for Similar Images. K. Grauman. Communications of the ACM, 2009. [CACM link]
-
Fast Image Search for Learned Metrics, P. Jain, B. Kulis, and K. Grauman, CVPR 2008. [pdf]
-
Small Codes and Large Image Databases for Recognition, A. Torralba, R. Fergus, and Y. Weiss, CVPR 2008. [pdf]
-
Object Retrieval with Large Vocabularies and Fast Spatial Matching. J. Philbin, O. Chum, M. Isard, J. Sivic, and A. Zisserman, CVPR 2007. [pdf] [approx k-means code]
- City-Scale
Location Recognition, G. Schindler, M. Brown, and R.
Szeliski, CVPR 2007. [pdf]
- LSH homepage
- Nearest Neighbor Methods in Learning and Vision, Shakhnarovich, Darrell, and Indyk, editors.
- CVPR 2009 Workshop on Visual Place Categorization
- Code for downloading Flickr images, by James Hays
- UW Community Photo Collections homepage
- INRIA Holiday images dataset
- NUS-WIDE tagged image dataset of 269K images
- MIRFlickr dataset
[wrap-up on instance recognition, large-scale search]
Global appearance models for category and scene recognition; sliding window detection, voting-based detection, detection as a binary decision problem.

-
*A Discriminatively Trained, Multiscale, Deformable Part Model, by P. Felzenszwalb, D. McAllester and D. Ramanan. CVPR 2008. [pdf] [code]
-
*Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories, Lazebnik, Schmid, and Ponce, CVPR 2006. [pdf] [15 scenes dataset] [libpmk] [Matlab]
-
*Class-specific Hough Forests for Object Detection. J. Gall and V. Lempitsky. CVPR 2009. [pdf] [slides] [code]
-
Robust Object Detection with Interleaved Categorization and Segmentation. B. Leibe, A. Leonardis, and B. Schiele. IJCV 2008. [pdf] [code]
-
The Devil is in the Details: an Evaluation of Recent Feature Encoding Methods. K. Chatfield, V. Lempitsky, A. Vedaldi, A. Zisserman. BMVC 2011. [pdf] [code]
-
Rapid Object Detection Using a Boosted Cascade of Simple Features, Viola and Jones, CVPR 2001. [pdf] [code]
-
Histograms of Oriented Gradients for Human Detection, Dalal and Triggs, CVPR 2005. [pdf] [video] [code] [PASCAL datasets]
-
Modeling the Shape of the Scene: a Holistic Representation of the Spatial Envelope, Oliva and Torralba, IJCV 2001. [pdf] [Gist code]
-
Locality-Constrained Linear Coding for Image Classification. J. Wang, J. Yang, K. Yu, and T. Huang CVPR 2010. [pdf] [code]
-
Visual Categorization with Bags of Keypoints, C. Dance, J. Willamowski, L. Fan, C. Bray, and G. Csurka, ECCV International Workshop on Statistical Learning in Computer Vision, 2004. [pdf]
-
Pedestrian Detection in Crowded Scenes, Leibe, Seemann, and Schiele, CVPR 2005. [pdf]
-
Pyramids of Histograms of Oriented Gradients (pHOG), Bosch and Zisserman. [code]
-
Sampling Strategies for Bag-of-Features Image Classification. E. Nowak, F. Jurie, and B. Triggs. ECCV 2006. [pdf]
-
Beyond Sliding Windows: Object Localization by Efficient Subwindow Search. C. Lampert, M. Blaschko, and T. Hofmann. CVPR 2008. [pdf] [code]
- Diagnosing Error in Object Detectors. D.
Hoiem et al. ECCV 2012. [pdf]
- VLFeat code
- LIBPMK feature extraction code, includes dense sampling
- LIBSVM library for support vector machines
- PASCAL
VOC
Visual
Object
Classes Challenge
[slides part 1]
Heath-expt
Nona-paper
Segmentation into regions, grouping, surface estimation

-
*Constrained Parametric Min-Cuts for Automatic Object Segmentation. J. Carreira and C. Sminchisescu. CVPR 2010. [pdf] [code]
-
*From Contours to Regions: An Empirical Evaluation. P. Arbelaez, M. Maire, C. Fowlkes, and J. Malik. CVPR 2009. [pdf] [code and data] [journal paper]
-
*Indoor
Segmentation and Support Inference from RGBD Images. N. Silberman, D.
Hoiem, P. Kohli, and R. Fergus. ECCV
2012. [pdf]
[NYU
depth dataset]
-
Geometric Context from a Single Image, D. Hoiem, A. Efros, and M. Hebert, ICCV 2005. [pdf] [web] [code]
-
Category Independent Object Proposals. I. Endres and D. Hoiem. ECCV 2010. [pdf] [code/data]
-
Geometric reasoning for single image structure recovery. D. Lee, M. Hebert, T. Kanade. CVPR 2009. [pdf] [code]
-
Boundary-Preserving Dense Local Regions. J. Kim and K. Grauman. CVPR 2011. [pdf] [code]
-
Object Recognition as Ranking Holistic Figure-Ground Hypotheses. F. Li, J. Carreira, and C. Sminchisescu. CVPR 2010. [pdf]
- People Watching: Human
Actions as a Cue for Single View Geometry. D.
Fouhey et al. ECCV 2012. [pdf]
-
Using Multiple Segmentations to Discover Objects and their Extent in Image Collections, B. C. Russell, A. A. Efros, J. Sivic, W. T. Freeman, and A. Zisserman. CVPR 2006. [pdf] [code]
-
Combining Top-down and Bottom-up Segmentation. E. Borenstein, E. Sharon, and S. Ullman. CVPR workshop 2004. [pdf] [data]
-
Learning Mid-level Features for Recognition. Y.-L. Boureau, F. Bach, Y. LeCun, and J. Ponce. CVPR, 2010.
-
Class-Specific, Top-Down Segmentation, E. Borenstein and S. Ullman, ECCV 2002. [pdf]
-
GrabCut -Interactive Foreground Extraction using Iterated Graph Cuts, by C. Rother, V. Kolmogorov, A. Blake, SIGGRAPH 2004. [pdf] [project page]
-
Robust Higher Order Potentials for Enforcing Label Consistency, P. Kohli, L. Ladicky, and P. Torr. CVPR 2008.
-
Collect-Cut: Segmentation with Top-Down Cues Discovered in Multi-Object Images. Y. J. Lee and K. Grauman. CVPR 2010. [pdf] [data]
- Shape Sharing for Object
Segmentation. J. Kim and K. Grauman.
ECCV 2012. [pdf]
-
Normalized Cuts and Image Segmentation, J. Shi and J. Malik. PAMI 2000. [pdf] [code]
- Fast
SLIC superpixels
- Greg Mori's superpixel code
- Berkeley Segmentation Dataset and code
- Pedro Felzenszwalb's graph-based segmentation code
- Mean-shift: a Robust Approach Towards Feature Space Analysis [pdf] [code, Matlab interface by Shai Bagon]
- David Blei's Topic modeling code
- Berkeley
3D object dataset (kinect)
[slides]
Che-Chun-expt
Elad-expt
Sanmit-paper
Islam-paper
Chao-paper
Multi-object scenes, inter-object relationships, understanding scenes' spatial layout

- *Scene Semantics from Long-term Observation of People. V. Delaitre, D. Fouhey, I. Laptev, J. Sivic, A. Gupta, A. Efros. ECCV 2012 [pdf] [web] [pose code]
-
*Using the Forest to See the Trees: Exploiting Context for Visual Object Detection and Localization. Torralba, Murphy, and Freeman. CACM 2009. [pdf] [related code]
-
Object-Graphs for Context-Aware Category Discovery. Y. J. Lee and K. Grauman. CVPR 2010. [pdf] [code]
-
Estimating Spatial Layout of Rooms using Volumetric Reasoning about Objects and Surfaces. D. Lee, A. Gupta, M. Hebert, and T. Kanade. NIPS 2010. [pdf] [code]
-
Contextual Priming for Object Detection, A. Torralba. IJCV 2003. [pdf] [web] [code]
-
Object Bank: A High-Level Image Representation for Scene Classification & Semantic Feature Sparsification. L-J. Li, H. Su, E. Xing, L. Fei-Fei. NIPS 2010. [pdf] [code]
-
RGB-D scene labeling: features and algorithms. X. Ren, L. Bo, and D. Fox. CVPR 2012. [pdf] [code]
-
TextonBoost: Joint Appearance, Shape and Context Modeling for Multi-Class Object Recognition and Segmentation. J. Shotton, J. Winn, C. Rother, A. Criminisi. ECCV 2006. [pdf] [web] [data] [code]
-
Recognition Using Visual Phrases. M. Sadeghi and A. Farhadi. CVPR 2011. [pdf]
-
Thinking Inside the Box: Using Appearance Models and Context Based on Room Geometry. V. Hedau, D. Hoiem, and D. Forsyth. ECCV 2010 [pdf] [code and data]
-
Blocks World Revisited: Image Understanding Using Qualitative Geometry and Mechanics, A. Gupta, A. Efros, and M. Hebert. ECCV 2010. [pdf] [code]
-
Geometric Reasoning for Single Image Structure Recovery. D. Lee, M. Hebert, and T. Kanade. CVPR 2009. [pdf] [web] [code]
-
Putting Objects in Perspective, by D. Hoiem, A. Efros, and M. Hebert, CVPR 2006. [pdf] [web]
-
Discriminative Models for Multi-Class Object Layout, C. Desai, D. Ramanan, C. Fowlkes. ICCV 2009. [pdf] [slides] [SVM struct code] [data]
-
Closing the Loop in Scene Interpretation. D. Hoiem, A. Efros, and M. Hebert. CVPR 2008. [pdf]
-
Decomposing a Scene into Geometric and Semantically Consistent Regions, S. Gould, R. Fulton, and D. Koller, ICCV 2009. [pdf] [slides]
-
Learning Spatial Context: Using Stuff to Find Things, by G. Heitz and D. Koller, ECCV 2008. [pdf] [code]
-
An Empirical Study of Context in Object Detection, S. Divvala, D. Hoiem, J. Hays, A. Efros, M. Hebert, CVPR 2009. [pdf] [web]
-
Object Categorization using Co-Occurrence, Location and Appearance, by C. Galleguillos, A. Rabinovich and S. Belongie, CVPR 2008.[ pdf]
-
Context Based Object Categorization: A Critical Survey. C. Galleguillos and S. Belongie. [pdf]
-
What, Where and Who? Classifying Events by Scene and Object Recognition, L.-J. Li and L. Fei-Fei, ICCV 2007. [pdf]
-
Simultaneous Visual Recognition of Manipulation Actions and Manipulated Objects. H. Kjellstrom et al. ECCV 2008. [pdf]
-
Modeling mutual context of object and human pose in human-object interaction activities. B. Yao and L. Fei-Fei. CVPR 2010. [pdf]
Aron-paper
Aashish-expt
David-expt
Sharing features between classes, transfer, taxonomy, learning from few examples, exploiting class relationships
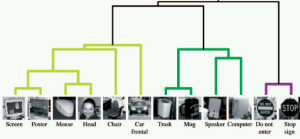
-
*Sharing Visual Features for Multiclass and Multiview Object Detection, A. Torralba, K. Murphy, W. Freeman, PAMI 2007. [pdf] [code]
-
*Hedging Your Bets: Optimizing Accuracy-Specificity Trade-offs in Large Scale Visual Recognition. J. Deng, J. Krause, A. Berg, L. Fei-Fei. CVPR 2012 [pdf] [supp] [ILSVRC data]
-
*Tabula Rasa: Model Transfer for Object Category Detection. Y. Atar and A. Zisserman. CVPR 2011. [pdf] [HoG code]
-
What Does Classifying More than 10,000 Image Categories Tell Us? J. Deng, A. Berg, K. Li and L. Fei-Fei. ECCV 2010. [pdf]
-
Discriminative Learning of Relaxed Hierarchy for Large-scale Visual Recognition. T. Gao and Daphne Koller. ICCV 2011. [pdf] [code]
-
Comparative Object Similarity for Improved Recognition with Few or Zero Examples. G. Wang, D. Forsyth, and D. Hoeim. CVPR 2010. [pdf]
-
Learning and Using Taxonomies for Fast Visual Categorization, G. Griffin and P. Perona, CVPR 2008. [pdf] [data]
-
80 Million Tiny Images: A Large Dataset for Non-Parametric Object and Scene Recognition, by A. Torralba, R. Fergus, and W. Freeman. PAMI 2008. [pdf] [web]
-
Constructing Category Hierarchies for Visual Recognition, M. Marszalek and C. Schmid. ECCV 2008. [pdf] [web] [Caltech256]
-
Learning Generative Visual Models from Few Training Examples: an Incremental Bayesian Approach Tested on 101 Object Categories. L. Fei-Fei, R. Fergus, and P. Perona. CVPR Workshop on Generative-Model Based Vision. 2004. [pdf] [Caltech101]
-
Towards Scalable Representations of Object Categories: Learning a Hierarchy of Parts. S. Fidler and A. Leonardis. CVPR 2007 [pdf]
-
Exploiting Object Hierarchy: Combining Models from Different Category Levels, A. Zweig and D. Weinshall, ICCV 2007 [pdf]
-
Incremental Learning of Object Detectors Using a Visual Shape Alphabet. Opelt, Pinz, and Zisserman, CVPR 2006. [pdf]
-
ImageNet: A Large-Scale Hierarchical Image Database, J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li and L. Fei-Fei, CVPR 2009 [pdf] [data]
-
Semantic Label Sharing for Learning with Many Categories. R. Fergus et al. ECCV 2010. [pdf]
-
Learning a Tree of Metrics with Disjoint Visual Features. S. J. Hwang, K. Grauman, F. Sha. NIPS 2011.
Gary-expt
Visual properties, learning from natural language descriptions, intermediate representations

- *FaceTracer: A Search Engine for Large
Collections of Images with Faces. N. Kumar, P.
Belhumeur, and S. Nayar. ECCV 2008. [pdf]
[code,
data, demo]
-
Attribute and Simile Classifiers for Face Verification, N. Kumar, A. Berg, P. Belhumeur, S. Nayar. ICCV 2009. [pdf] [web] [lfw data] [pubfig data]
-
Learning To Detect Unseen Object Classes by Between-Class Attribute Transfer, C. Lampert, H. Nickisch, and S. Harmeling, CVPR 2009 [pdf] [web] [data]
-
A Joint Learning Framework for Attribute Models and Object Descriptions. D. Mahajan, S. Sellamanickam, V. Nair. ICCV 2011. [pdf]
- WhittleSearch: Image Search with Relative
Attribute Feedback. A. Kovashka, D. Parikh, K.
Grauman. CVPR 2012. [pdf]
[data]
-
SUN Attribute Database: Discovering, Annotating, and Recognizing Scene Attributes. G. Patterson and J. Hays. CVPR 2012. [pdf] [data]
-
Multi-Attribute Spaces: Calibration for Attribute Fusion and Similarity Search. W. Scheirer, N. Kumar, P. Belhumeur, T. Boult. CVPR 2012 [pdf]
-
A Discriminative Latent Model of Object Classes and Attributes. Y. Wang and G. Mori. ECCV, 2010. [pdf]
-
Learning Visual Attributes, V. Ferrari and A. Zisserman, NIPS 2007. [pdf]
-
Learning Models for Object Recognition from Natural Language Descriptions, J. Wang, K. Markert, and M. Everingham, BMVC 2009.[pdf]
-
Attribute-Centric Recognition for Cross-Category Generalization. A. Farhadi, I. Endres, D. Hoiem. CVPR 2010. [pdf]
-
Automatic Attribute Discovery and Characterization from Noisy Web Data. T. Berg et al. ECCV 2010. [pdf] [data]
-
Attributes-Based People Search in Surveillance Environments. D. Vaquero, R. Feris, D. Tran, L. Brown, A. Hampapur, and M. Turk. WACV 2009. [pdf] [project page]
-
Image Region Entropy: A Measure of "Visualness" of Web Images Associated with One Concept. K. Yanai and K. Barnard. ACM MM 2005. [pdf]
-
What Helps Where And Why? Semantic Relatedness for Knowledge Transfer. M. Rohrbach, M. Stark, G. Szarvas, I. Gurevych and B. Schiele. CVPR 2010. [pdf]
-
Recognizing Human Actions by Attributes. J. Liu, B. Kuipers, S. Savarese, CVPR 2011. [pdf]
-
Interactively Building a Discriminative Vocabulary of Nameable Attributes. D. Parikh and K. Grauman. CVPR 2011. [pdf] [web]
- Animals with Attributes dataset
- aYahoo and aPascal attributes datasets
- Attribute discovery dataset of shopping categories
- Public Figures Face database with attributes
- Relative attributes data
- WhittleSearch relative attributes data
- SUN Scenes attribute dataset
- Cross-category object recognition (CORE) dataset
- Leeds Butterfly Dataset
- FaceTracer database from Columbia
- Caltech-UCSD Birds dataset
- Database
of human attributes
Girish-paper
Sanmit-expt
Nona-expt
Among all items in the scene, which deserve attention (first)? What makes images interesting or memorable?

- *Understanding and Predicting Importance in
Images. A. Berg et al. CVPR 2012. [pdf]
[UIUC
sentence dataset] [ImageClef
dataset]
-
*Learning to Detect a Salient Object. T. Liu et al. CVPR 2007. [pdf] [results] [data] [code]
-
*What Makes an Image Memorable? P. Isola, J. Xiao, A. Torralba, A. Oliva. CVPR 2011. [pdf] [web] [code/data]
-
What Do We Perceive in a Glance of a Real-World Scene? L. Fei-Fei, A. Iyer, C. Koch, and P. Perona. Journal of Vision, 2007. [pdf]
-
A Model of Saliency-based Visual Attention for Rapid Scene Analysis. L. Itti, C. Koch, and E. Niebur. PAMI 1998 [pdf]
-
Interesting Objects are Visually Salient. L. Elazary and L. Itti. Journal of Vision, 8(3):1–15, 2008. [pdf]
-
Accounting for the Relative Importance of Objects in Image Retrieval. S. J. Hwang and K. Grauman. BMVC 2010. [pdf] [web] [data]
-
Some Objects are More Equal Than Others: Measuring and Predicting Importance, M. Spain and P. Perona. ECCV 2008. [pdf]
-
The Discriminant Center-Surround Hypothesis for Bottom-Up Saliency. D. Gao, V.Mahadevan, and N. Vasconcelos. NIPS, 2007. [pdf]
-
What is an Object? B. Alexe, T. Deselaers, and V. Ferrari. CVPR 2010. [pdf] [code]
-
A Principled Approach to Detecting Surprising Events in Video. L. Itti and P. Baldi. CVPR 2005 [pdf]
-
What Attributes Guide the Deployment of Visual Attention and How Do They Do It? J. Wolfe and T. Horowitz. Neuroscience, 5:495–501, 2004. [pdf]
-
Visual Correlates of Fixation Selection: Effects of Scale and Time. B. Tatler, R. Baddeley, and I. Gilchrist. Vision Research, 45:643, 2005. [pdf]
-
Objects Predict Fixations Better than Early Saliency. W. Einhauser, M. Spain, and P. Perona. Journal of Vision, 8(14):1–26, 2008. [pdf]
-
Reading Between the Lines: Object Localization Using Implicit Cues from Image Tags. S. J. Hwang and K. Grauman. CVPR 2010. [pdf]
-
Peripheral-Foveal Vision for Real-time Object Recognition and Tracking in Video. S. Gould, J. Arfvidsson, A. Kaehler, B. Sapp, M. Messner, G. Bradski, P. Baumstrack,S. Chung, A. Ng. IJCAI 2007. [pdf]
-
Determining Patch Saliency Using Low-Level Context, D. Parikh, L. Zitnick, and T. Chen. ECCV 2008. [pdf]
-
Key-Segments for Video Object Segmentation. Y. J. Lee, J. Kim, and K. Grauman. ICCV 2011 [pdf]
-
Contextual Guidance of Eye Movements and Attention in Real-World Scenes: The Role of Global Features on Object Search. A. Torralba, A. Oliva, M. Castelhano, J. Henderson. [pdf] [web]
-
The Role of Top-down and Bottom-up Processes in Guiding Eye Movements during Visual Search, G. Zelinsky, W. Zhang, B. Yu, X. Chen, D. Samaras, NIPS 2005. [pdf]
Chao-expt
Che-Chun-paper
Niveda-paper
Finding people, predicting their poses and attributes, automatic face tagging

-
*Poselets: Body Part Detectors Trained Using 3D Human Pose Annotations, L. Bourdev and J. Malik. ICCV 2009 [pdf] [code]
-
*Real-Time Human Pose Recognition in Parts from a Single Depth Image. J. Shotton et al. CVPR 2011. [pdf] [video] [web]
-
*Where’s Waldo: Matching People in Images of Crowds. R. Garg, D. Ramanan, S. Seitz, N. Snavely. CVPR 2011. [pdf] [web]
-
*Understanding Images of Groups of People, A. Gallagher and T. Chen, CVPR 2009. [pdf] [web] [data]
- Parsing Clothing in Fashion Photographs.
K. Yamaguchi et al. CVPR 2012. [pdf]
[data]
-
Contextual Identity Recognition in Personal Photo Albums. D. Anguelov, K.-C. Lee, S. Burak, Gokturk, and B. Sumengen. CVPR 2007. [pdf]
- Recognizing Proxemics in Personal
Photos. Y. Yang, S. Baker, A. Kannan, D.
Ramanan. CVPR 2012. [pdf]
-
Who are you? - Learning Person Specific Classifiers from Video, J. Sivic, M. Everingham, and A. Zisserman, CVPR 2009. [pdf] [data] [KLT tracking code]
-
Describing Clothing by Semantic Attributes. A. Gallagher et al. ECCV 2012. [pdf]
-
Describing People: A Poselet-Based Approach to Attribute Classification. L. Bourdev, S. Maji, J. Malik. ICCV 2011. [pdf]
- Weakly Supervised Learning of Interactions
between Humans and Objects. Prest et al. PAMI
2012. [pdf]
-
Finding and Tracking People From the Bottom Up. D. Ramanan, D. A. Forsyth. CVPR 2003. [pdf]
-
Autotagging Facebook: Social Network Context Improves Photo Annotation, by Z. Stone, T. Zickler, and T. Darrell. CVPR Internet Vision Workshop 2008. [pdf]
-
Efficient Propagation for Face Annotation in Family Albums. L. Zhang, Y. Hu, M. Li, and H. Zhang. MM 2004. [pdf]
-
Progressive Search Space Reduction for Human Pose Estimation. Ferrari, V., Marin-Jimenez, M. and Zisserman, A. CVPR 2008. [pdf] [web] [code]
-
Names and Faces in the News, by T. Berg, A. Berg, J. Edwards, M. Maire, R. White, Y. Teh, E. Learned-Miller and D. Forsyth, CVPR 2004. [pdf] [web]
-
Face Discovery with Social Context. Y. J. Lee and K. Grauman. BMVC 2011. [pdf]
-
“Hello! My name is... Buffy” – Automatic Naming of Characters in TV Video, by M. Everingham, J. Sivic and A. Zisserman, BMVC 2006. [pdf] [web] [data]
-
Pictorial Structures Revisited: People Detection and Articulated Pose Estimation. M. Andriluka et al. CVPR 2009. [pdf] [code]
- Exploring Photobios. I. Kemelmacher-Shlizerman, E. Shechtman, R. Garg, S. Seitz. SIGGRAPH 2011. [pdf]
- Face detection code in OpenCV
- Gallagher's Person Dataset
- Face data from Buffy episode, from Oxford Visual Geometry Group
- CALVIN upper-body detector code
- UMass Labeled Faces in the Wild
- FaceTracer database from Columbia
- Database
of human attributes
Randall-expt
Aron-expt
Dinesh-paper
Recognizing and localizing human actions in video or static images

-
*Learning Realistic Human Actions from Movies. I. Laptev, M. Marszałek, C. Schmid and B. Rozenfeld. CVPR 2008. [pdf] [data] [code]
-
*A Unified Framework for Multi-Target Tracking and Collective Activity Recognition. W. Choi and S. Savarese. ECCV 2012. [pdf] [web] [video] [data]
-
*Detecting Actions, Poses, and Objects with Relational Phraselets. C. Desai and D. Ramanan. ECCV 2012. [pdf] [data] [code]
-
Beyond Actions: Discriminative Models for Contextual Group Activities. T. Lian, Y. Wang, W. Yang, and G. Mori. NIPS 2010. [pdf] [data]
-
Efficient Activity Detection with Max-Subgraph Search. C.-Y. Chen and K. Grauman. CVPR 2012. [pdf] [project page] [code]
-
Action Bank: a High-Level Representation of Activity in Video. S. Sadanand and J. Corso. CVPR 2012 [pdf] [code/data]
-
A Hough Transform-Based Voting Framework for Action Recognition. A. Yao, J. Gall, L. Van Gool. CVPR 2010. [pdf] [code/data]
-
Actions in Context, M. Marszalek, I. Laptev, C. Schmid. CVPR 2009. [pdf] [web] [data]
-
Objects in Action: An Approach for Combining Action Understanding and Object Perception. A. Gupta and L. Davis. CVPR, 2007. [pdf] [data]
- Exemplar-based Action Recognition in Video. G.
Willems, J. Becker, T. Tuytelaars, and L. V. Gool. BMVC,
2009.
-
A Scalable Approach to Activity Recognition Based on Object Use. J. Wu, A. Osuntogun, T. Choudhury, M. Philipose, and J. Rehg. ICCV 2007. [pdf]
-
Recognizing Actions at a Distance. A. Efros, G. Mori, J. Malik. ICCV 2003. [pdf] [web]
-
Action Recognition from a Distributed Representation of Pose and Appearance, S. Maji, L. Bourdev, J. Malik, CVPR 2011. [pdf] [code]
-
Learning a Hierarchy of Discriminative Space-Time Neighborhood Features for Human Action Recognition. A. Kovashka and K. Grauman. CVPR 2010. [pdf]
-
Temporal Causality for the Analysis of Visual Events. K. Prabhakar, S. Oh, P. Wang, G. Abowd, and J. Rehg. CVPR 2010. [pdf] [Georgia Tech Computational Behavior Science project]
-
What's Going on?: Discovering Spatio-Temporal Dependencies in Dynamic Scenes. D. Kuettel et al. CVPR 2010. [pdf]
-
Learning Actions From the Web. N. Ikizler-Cinbis, R. Gokberk Cinbis, S. Sclaroff. ICCV 2009. [pdf]
- Ivan Laptev's Space-Time Interest Points code
- Hollywood activity dataset
- Stanford 40 Actions still image dataset
- Stanford
People Playing Musical Instrument dataset
- UCF activity datasets
- PASCAL VOC action recognition taster challenge
- Greg Mori and Ivan Laptev's tutorial on action recognition at ECCV 2010
- TRECVID video retrieval challenge
- UMich Collective Activity dataset
Gary-paper
David-paper
Analyzing data from wearable, mobile cameras; "first person" vision

- *Social Interactions: A First-Person Perspective. A. Fathi, J. Hodgins, J. Rehg. CVPR 2012 [pdf] [data]
-
*Recognizing Activities of Daily Living in First-Person Camera Views. H. Pirsiavash and D. Ramanan. CVPR 2012. [pdf] [data/code]
-
*Novelty Detection from an Egocentric Perspective. O. Aghazadeh, J. Sullivan, and S. Carlsson. CVPR 2011 [pdf] [web/data]
- Discovering Important People and Objects for Egocentric Video Summarization. Y. J. Lee, J. Ghosh, and K. Grauman. CVPR 2012. [pdf] [web]
-
Understanding Egocentric Activities. A. Fathi, A. Farhadi, J. Rehg. ICCV 2011. [pdf] [data]
- Learning to Recognize Objects in Egocentric Activities. A. Fathi, X. Ren, J. Rehg. CVPR 2011. [pdf]
-
Figure-Ground Segmentation Improves Handled Object Recognition in Egocentric Video. X. Ren and C. Gu. CVPR 2010 [pdf] [videos] [data]
-
Egocentric Recognition of Handled Objects: Benchmark and Analysis. X. Ren and M. Philipose. Egovision Workshop 2009. [pdf] [data]
-
Activity Recognition from First Person Sensing. E. Taralova, F. De la Torre, M. Hebert CVPR 2009 Workshop on Egocentric Vision [pdf]
-
Close-Range Human Detection for Head-Mounted Cameras. D. Mitzel and B. Leibe. BMVC 2012. [pdf]
-
Structural Epitome: A Way to Summarize One’s Visual Experience. N. Jojic, A. Perina, and V. Murino. NIPS 2010. [pdf]
-
Fast Unsupervised Ego-Action Learning for First-Person Sports Video. K. Kitani, T. Okabe, Y. Sato, and A. Sugimoto. CVPR 2011. [pdf]
-
Wearable Hand Activity Recognition for Event Summarization. W. Mayol and D. Murray. International Symposium on Wearable Computers. IEEE, 2005. [pdf]
-
Illumination-free Gaze Estimation Method for First-Person Vision Wearable Device. A. Tsukada, M. Shino, M. Devyver, T. Kanade. ICCV Workshop 2011. [pdf]
- Egovision
workshop at CVPR 2012
Randall-paper
Dinesh-expt
Human-in-the-loop learning, active annotation collection, crowdsourcing
-
*Multiclass Recognition and Part Localization with Humans in the Loop. C. Wah et al. ICCV 2011. [pdf] [Caltech/UCSD Visipedia project] [data]
-
*What’s It Going to Cost You? : Predicting Effort vs. Informativeness for Multi-Label Image Annotations. S. Vijayanarasimhan and K. Grauman. CVPR 2009 [pdf] [data] [code]
-
*The Multidimensional Wisdom of Crowds. Welinder P., Branson S., Belongie S., Perona, P. NIPS 2010. [pdf] [code]
- Visual Recognition with Humans in the
Loop. Branson S., Wah C.,
Babenko B., Schroff F., Welinder P., Perona P.,
Belongie S. ECCV 2010. [pdf]
-
Large-Scale Live Active Learning: Training Object Detectors with Crawled Data and Crowds. S. Vijayanarasimhan and K. Grauman. CVPR 2011. [pdf]
-
WhittleSearch: Image Search with Relative Attribute Feedback. A. Kovashka, D. Parikh, K. Grauman. CVPR 2012. [pdf] [data]
-
Crowdclustering. R. Gomes, P. Welinder, A. Krause, P. Perona. NIPS 2011. [pdf]
-
Adaptively Learning the Crowd Kernel. O. Tamuz, C. Liu, S. Belongie, O. Shamir, A. Kalai. ICML 2011 [pdf]
-
LeafSnap: A Computer Vision System for Automatic Plant Species Identification. N. Kumar et al. ECCV 2012. [pdf]
- Interactive Object Detection. A. Yao, J.
Gall, C. Leistner, L. Van Gool. CVPR 2012. [pdf]
-
Efficiently Scaling Up Video Annotation with Crowdsourced Marketplaces. C. Vondrick, D. Ramanan, D. Patterson. ECCV 2010. [pdf] [data/code]
-
Video Annotation and Tracking with Active Learning. C. Vondrick, D. Patterson, D. Ramanan. NIPS 2011. [pdf] [code]
-
Active Frame Selection for Label Propagation in Videos. S. Vijayanarasimhan and K. Grauman. ECCV 2012. [pdf]
-
Annotator Rationales for Visual Recognition. J. Donahue and K. Grauman. ICCV 2011. [pdf]
- Attributes for Classifier Feedback. A.
Parkash and D. Parikh. ECCV 2012. [pdf]
-
Combining Self Training and Active Learning for Video Segmentation. A. Fathi, M. Balcan, X. Ren, J. Rehg. BMVC 2011. [pdf]
-
Labeling Images with a Computer Game. L. von Ahn and L. Dabbish. CHI, 2004.
- Whose Vote Should Count More: Optimal
Integration of Labels from Labelers of Unknown
Expertise. J. Whitehill et al. NIPS
2009. [pdf]
-
Utility Data Annotation with Amazon Mechanical Turk. A. Sorokin and D. Forsyth. Wkshp on Internet Vision, 2008.
-
Far-Sighted Active Learning on a Budget for Image and Video Recognition. S. Vijayanarasimhan, P. Jain, and K. Grauman. CVPR 2010. [pdf] [code]
-
Active Learning from Crowds. Y. Yan, R. Rosales, G. Fung, J. Dy. ICML 2011. [pdf]
- Proactive Learning:
Cost-Sensitive Active Learning with Multiple
Imperfect Oracles. P. Donmez and J.
Carbonell. CIKM 2008. [pdf]
-
Inactive Learning? Difficulties Employing Active Learning in Practice. J. Attenberg and F. Provost. SIGKDD 2011. [pdf]
-
Actively Selecting Annotations Among Objects and Attributes. A. Kovashka, S. Vijayanarasimhan, and K. Grauman. ICCV 2011 [pdf]
- Supervised
Learning from Multiple Experts: Whom to Trust When
Everyone Lies a Bit. V. Raykar et al.
ICML 2009. [pdf]
-
Multi-class Active Learning for Image Classification. A. J. Joshi, F. Porikli, and N. Papanikolopoulos. CVPR 2009. [pdf]
-
GrabCut -Interactive Foreground Extraction using Iterated Graph Cuts, by C. Rother, V. Kolmogorov, A. Blake, SIGGRAPH 2004. [pdf] [project page]
- Peekaboom: A Game for Locating Objects in Images, by L. von Ahn, R. Liu and M. Blum, CHI 2006. [pdf] [web]
Heath-paper
Niveda-expt