Remark 2.2.1
If the material in this section makes you scratch your head, you may want to go through the materials in Week 5 of our other MOOC: https://www.edx.org/course/laff-linear-algebra-foundations-to-frontiers.
If the material in this section makes you scratch your head, you may want to go through the materials in Week 5 of our other MOOC: https://www.edx.org/course/laff-linear-algebra-foundations-to-frontiers.
Key to understanding how we are going to optimize matrix-matrix multiplication is to understand blocked matrix-matrix multiplication (the multiplication of matrices that have been partitioned into submatrices).
Consider \(C := A B + C \text{.}\) In terms of the elements of the matrices, this means that each \(\gamma_{i,j} \) is computed by
Now, partition the matrices into submatrices:
and
where
\(C_{i,j} \) is \(m_i \times n_j \text{,}\)
\(A_{i,p} \) is \(m_i \times k_p \text{,}\) and
\(B_{p,j} \) is \(k_p \times n_j \)
with \(\sum_{i=0}^{M-1} m_i = m \text{,}\) \(\sum_{j=0}^{N-1} n_i = m \text{,}\) and \(\sum_{p=0}^{K-1} k_i = m \text{.}\) Then
In other words, provided the partitioning of the matrices is "conformal," matrix-matrix multiplication with partitioned matrices proceeds exactly as does matrix-matrix multiplication with the elements of the matrices except that the individual multiplications with the submatrices do not necessarily commute.
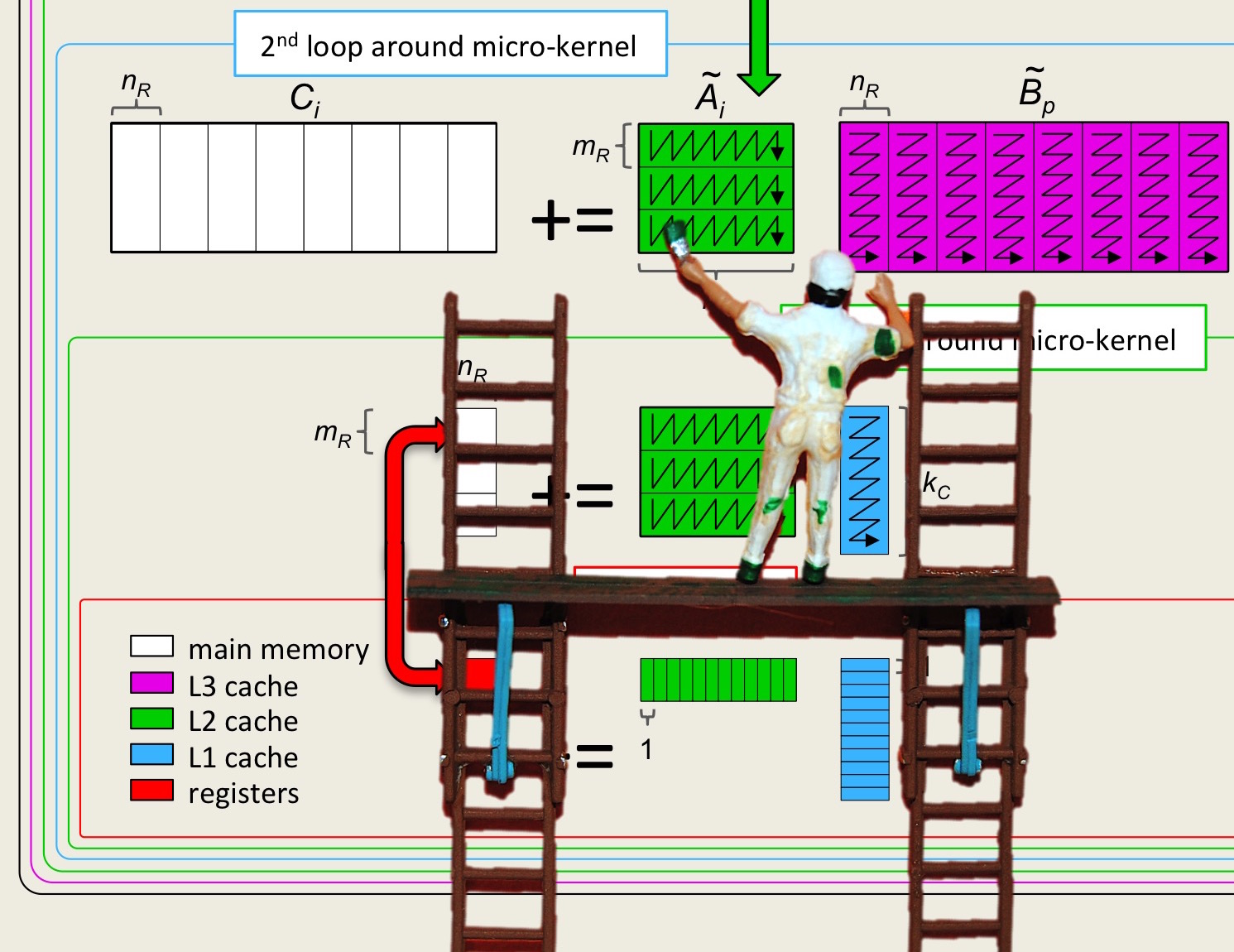
We illustrate how blocking \(C \) into \(m_b \times n_b\) submatrices, \(A \) into \(m_b \times n_b \) submatrices, and \(B \) into \(k_b \times n_b \) submatrices in Figure 2.2.3.

void MyGemm( int m, int n, int k, double *A, int ldA,
double *B, int ldB, double *C, int ldC )
{
for ( int j=0; j<n; j+=NB ){
int jb = min( n-j, NB ); /* Size for "finge" block */
for ( int i=0; i<m; i+=MB ){
int ib = min( m-i, MB ); /* Size for "finge" block */
for ( int p=0; p<k; p+=KB ){
int pb = min( k-p, KB ); /* Size for "finge" block */
Gemm_mbxnbxkb( ib, jb, pb, &alpha( i,p ), ldA, &beta( p,j ), ldB,
&gamma( i,j ), ldC );
}
}
}
}
void Gemm_mbxnbxkb( int m, int n, int k, double *A, int ldA,
double *B, int ldB, double *C, int ldC )
{
for ( int p=0; p<k; p++ )
for ( int j=0; j<n; j++ )
for ( int i=0; i<m; i++ )
gamma( i,j ) += alpha( i,p ) * beta( p,j );
}
In directory Assignments/Week2/C examine and time the code in file Assignments/Week2/C/Gemm_IJP_mbxnbxkb.c by executing
make IJP_mbxnbxkbView its performance with
Assignments/Week2/C/data/Plot_Blocked_MMM.mlxWe already employed various cases of blocked matrix-matrix multiplication in Week 1.
In Section 1.3 we already used the blocking of matrices to cast matrix-matrix multiplications in terms of dot products and axpy operations. This is captured in

In Section 1.4, we already used the blocking of matrices to cast matrix-matrix multiplications in terms of matrix-vector multiplication and rank-1 updates. This is captured in
